Contract rules for InfraMachine
Infrastructure providers SHOULD implement an InfraMachine resource using Kubernetes’ CustomResourceDefinition (CRD).
The goal of an InfraMachine resource is to manage the lifecycle of a provider-specific machine instances. These may be physical or virtual instances, and they represent the infrastructure for Kubernetes nodes.
The InfraMachine resource will be referenced by one of the Cluster API core resources, Machine.
The Machine’s controller will be responsible to coordinate operations of the InfraMachine, and the interaction between the Machine’s controller and the InfraMachine resource is based on the contract rules defined in this page.
Once contract rules are satisfied by an InfraMachine implementation, other implementation details could be addressed according to the specific needs (Cluster API is not prescriptive).
Nevertheless, it is always recommended to take a look at Cluster API controllers, in-tree providers, other providers and use them as a reference implementation (unless custom solutions are required in order to address very specific needs).
In order to facilitate the initial design for each InfraMachine resource, a few implementation best practices and infrastructure Provider Security Guidance are explicitly called out in dedicated pages.
Rules (contract version v1beta2)
| Rule | Mandatory | Note |
|---|---|---|
| All resources: scope | Yes | |
All resources: TypeMeta and ObjectMetafield | Yes | |
All resources: APIVersion field value | Yes | |
| InfraMachine, InfraMachineList resource definition | Yes | |
| InfraMachine: provider ID | Yes | |
| InfraMachine: failure domain | No | |
| InfraMachine: addresses | No | |
| InfraMachine: initialization completed | Yes | |
| InfraMachine: conditions | No | |
| InfraMachine: terminal failures | No | |
| InfraMachine: support for in-place changes | No | |
| InfraMachineTemplate, InfraMachineTemplateList resource definition | Yes | |
| InfraMachineTemplate: support for SSA dry run | No | Mandatory for ClusterClasses support |
| Multi tenancy | No | Mandatory for clusterctl CLI support |
| Clusterctl support | No | Mandatory for clusterctl CLI support |
| InfraMachine: pausing | No | |
| InfraMachineTemplate: support cluster autoscaling from zero | No |
Note:
All resourcesrefers to all the provider’s resources “core” Cluster API interacts with; In the context of this page:InfraMachine,InfraMachineTemplateand corresponding list types
All resources: scope
All resources MUST be namespace-scoped.
All resources: TypeMeta and ObjectMeta field
All resources MUST have the standard Kubernetes TypeMeta and ObjectMeta fields.
All resources: APIVersion field value
In Kubernetes APIVersion is a combination of API group and version.
Special consideration MUST applies to both API group and version for all the resources Cluster API interacts with.
All resources: API group
The domain for Cluster API resources is cluster.x-k8s.io, and infrastructure providers under the Kubernetes SIGS org
generally use infrastructure.cluster.x-k8s.io as API group.
If your provider uses a different API group, you MUST grant full read/write RBAC permissions for resources in your API group
to the Cluster API core controllers. If any resource sets another resource as the owner with blockOwnerDeletion set,
additional RBAC to update finalizers on the owner resource is required.
The canonical way to do so is via a ClusterRole resource with the aggregation label cluster.x-k8s.io/aggregate-to-manager: "true".
The following is an example ClusterRole for a FooMachine resource in the infrastructure.foo.com API group:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: capi-foo-clusters
labels:
cluster.x-k8s.io/aggregate-to-manager: "true"
rules:
- apiGroups:
- infrastructure.foo.com
resources:
- foomachines
- foomachinetemplates
verbs:
- create
- delete
- get
- list
- patch
- update
- watch
Note: The write permissions are required because Cluster API manages InfraMachines generated from InfraMachineTemplates; when using ClusterClass and managed topologies, also InfraMachineTemplates are managed directly by Cluster API.
All resources: version
The resource Version defines the stability of the API and its backward compatibility guarantees.
Examples include v1alpha1, v1beta1, v1, etc. and are governed by the Kubernetes API Deprecation Policy.
Your provider SHOULD abide by the same policies.
Note: The version of your provider does not need to be in sync with the version of core Cluster API resources. Instead, prefer choosing a version that matches the stability of the provider API and its backward compatibility guarantees.
Additionally:
Providers MUST set cluster.x-k8s.io/<version> label on the InfraMachine Custom Resource Definitions.
The label is a map from a Cluster API contract version to your Custom Resource Definition versions. The value is an underscore-delimited (_) list of versions. Each value MUST point to an available version in your CRD Spec.
The label allows Cluster API controllers to perform automatic conversions for object references, the controllers will pick the last available version in the list if multiple versions are found.
To apply the label to CRDs it’s possible to use labels in your kustomization.yaml file, usually in config/crd:
labels:
- pairs:
cluster.x-k8s.io/v1beta1: v1beta1
cluster.x-k8s.io/v1beta2: v1beta2
An example of this is in the Kubeadm Bootstrap provider.
InfraMachine, InfraMachineList resource definition
You MUST define a InfraMachine resource.
The InfraMachine resource name must have the format produced by sigs.k8s.io/cluster-api/util/contract.CalculateCRDName(Group, Kind).
Note: Cluster API is using such a naming convention to avoid an expensive CRD lookup operation when looking for labels from the CRD definition of the InfraMachine resource.
It is a generally applied convention to use names in the format ${env}Machine, where ${env} is a, possibly short, name
for the environment in question. For example GCPMachine is an implementation for the Google Cloud Platform, and AWSMachine
is one for Amazon Web Services.
// +kubebuilder:object:root=true
// +kubebuilder:resource:path=foomachines,shortName=foom,scope=Namespaced,categories=cluster-api
// +kubebuilder:storageversion
// +kubebuilder:subresource:status
// FooMachine is the Schema for foomachines.
type FooMachine struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec FooMachineSpec `json:"spec,omitempty"`
Status FooMachineStatus `json:"status,omitempty"`
}
type FooMachineSpec struct {
// See other rules for more details about mandatory/optional fields in InfraMachine spec.
// Other fields SHOULD be added based on the needs of your provider.
}
type FooMachineStatus struct {
// See other rules for more details about mandatory/optional fields in InfraMachine status.
// Other fields SHOULD be added based on the needs of your provider.
}
For each InfraMachine resource, you MUST also add the corresponding list resource.
The list resource MUST be named as <InfraMachine>List.
// +kubebuilder:object:root=true
// FooMachineList contains a list of foomachines.
type FooMachineList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []FooMachine `json:"items"`
}
InfraMachine: provider ID
Each Machine needs a provider ID to identify the Kubernetes Node that runs on the machine.
Node’s Provider id MUST surface on spec.providerID in the InfraMachine resource.
type FooMachineSpec struct {
// providerID must match the provider ID as seen on the node object corresponding to this machine.
// For Kubernetes Nodes running on the Foo provider, this value is set by the corresponding CPI component
// and it has the format docker:////<vm-name>.
// +optional
// +kubebuilder:validation:MinLength=1
// +kubebuilder:validation:MaxLength=512
ProviderID string `json:"providerID,omitempty"`
// See other rules for more details about mandatory/optional fields in InfraMachine spec.
// Other fields SHOULD be added based on the needs of your provider.
}
NOTE: To align with API conventions, we recommend since the v1beta2 contract that the ProviderID field should be
of type string (it was *string before). Both are compatible with the v1beta2 contract though.
Once spec.providerID is set on the InfraMachine resource and the [InfraMachine initialization completed],
the Cluster controller will surface this info in Machine’s spec.providerID.
InfraMachine: failure domain
In case you are developing an infrastructure provider which has a notion of failure domains where machines should be
placed in, the InfraMachine resource MUST comply to the value that exists in the spec.failureDomain field of the Machine
(in other words, the InfraMachine MUST be placed in the failure domain specified at Machine level).
Also, InfraMachine providers are allowed to surface the failure domain where the machine is actually placed by
implementing the status.failureDomain field; this info, if present, will then surface at Machine level in a
corresponding field (also in status).
type FooMachineStatus struct {
// failureDomain is the unique identifier of the failure domain where this Machine has been placed in.
// +optional
// +kubebuilder:validation:MinLength=1
// +kubebuilder:validation:MaxLength=256
FailureDomain string `json:"failureDomain,omitempty"`
// See other rules for more details about mandatory/optional fields in InfraMachineStatus.
// Other fields SHOULD be added based on the needs of your provider.
}
InfraMachine: addresses
Infrastructure provider have the opportunity to surface machines addresses on the InfraMachine resource; this information won’t be used by core Cluster API controller, but it is really useful for operator troubleshooting issues on machines.
In case you want to surface machine’s addresses, you MUST surface them in status.addresses in the InfraMachine resource.
type FooMachineStatus struct {
// addresses contains the associated addresses for the machine.
// +optional
Addresses []clusterv1.MachineAddress `json:"addresses,omitempty"`
// See other rules for more details about mandatory/optional fields in InfraMachine status.
// Other fields SHOULD be added based on the needs of your provider.
}
Each MachineAddress must have a type; accepted types are Hostname, ExternalIP, InternalIP, ExternalDNS or InternalDNS.
Once status.addresses is set on the InfraMachine resource and the [InfraMachine initialization completed],
the Machine controller will surface this info in Machine’s status.addresses.
InfraMachine: initialization completed
Each InfraMachine MUST report when Machine’s infrastructure is fully provisioned (initialization) by setting
status.initialization.provisioned in the InfraMachine resource.
type FooMachineStatus struct {
// initialization provides observations of the FooMachine initialization process.
// NOTE: Fields in this struct are part of the Cluster API contract and are used to orchestrate initial Machine provisioning.
// +optional
Initialization FooMachineInitializationStatus `json:"initialization,omitempty,omitzero"`
// See other rules for more details about mandatory/optional fields in InfraMachine status.
// Other fields SHOULD be added based on the needs of your provider.
}
// FooMachineInitializationStatus provides observations of the FooMachine initialization process.
// +kubebuilder:validation:MinProperties=1
type FooMachineInitializationStatus struct {
// provisioned is true when the infrastructure provider reports that the Machine's infrastructure is fully provisioned.
// NOTE: this field is part of the Cluster API contract, and it is used to orchestrate initial Machine provisioning.
// +optional
Provisioned *bool `json:"provisioned,omitempty"`
}
Once status.initialization.provisioned is set the Machine “core” controller will bubble up this info in Machine’s
status.initialization.infrastructureProvisioned; also InfraMachine’s spec.providerID, status.failureDomain and status.addresses will
be surfaced on Machine’s corresponding fields at the same time.
InfraMachine: conditions
According to Kubernetes API Conventions, Conditions provide a standard mechanism for higher-level status reporting from a controller.
Providers implementers SHOULD implement status.conditions for their InfraMachine resource.
In case conditions are implemented on a InfraMachine resource, Cluster API will only consider conditions providing the following information:
type(required)status(required, one of True, False, Unknown)reason(optional, if omitted a default one will be used)message(optional, if omitted an empty message will be used)lastTransitionTime(optional, if omitted time.Now will be used)observedGeneration(optional, if omitted the generation of the InfraMachine resource will be used)
Other fields will be ignored.
If a condition with type Ready exist, such condition will be mirrored in Machine’s InfrastructureReady condition.
Please note that the Ready condition is expected to surface the status of the InfraMachine during its own entire lifecycle,
including initial provisioning, the final deletion process, and the period in between these two moments.
See Improving status in CAPI resources for more context.
InfraMachine: terminal failures
Starting from the v1beta2 contract version, there is no more special treatment for provider’s terminal failures within Cluster API.
In case necessary, “terminal failures” should be surfaced using conditions, with a well documented type/reason; it is up to consumers to treat them accordingly.
See Improving status in CAPI resources for more context.
InfraMachine: support for in-place changes
In case you are developing an infrastructure provider with support for in-place updates of the Machine infrastructure, you should consider following recommendations during implementation.
- The
Update Extensionis the component responsible for orchestrating in-place changes on Machines. Accordingly, the InfraMachine controller should ignore in-place changes. As alternative the InfraMachine controller must orchestrate those changes with theUpdate Extension(e.g. theUpdate Extensionmust report change progress). - It might be useful to start thinking about the InfraMachine API surface as a set of fields with one of the following behaviors:
- “Immutable” fields that can only be changed by performing a rollout.
- “Mutable” fields that will be “reconciled” by the
Update Extension. - Fields written back to spec by the infra provider (e.g. ProviderID).
- The validation webhook for the InfraMachine CR should allow changes to “mutable” fields; in case an infra provider wants to allow this change selectively, e.g. only when applied by core CAPI, please reach out to maintainers to discuss options.
- Please note that the above field classification do not apply to the InfraMachineTemplate object.
See Proposal.
InfraMachineTemplate, InfraMachineTemplateList resource definition
For a given InfraMachine resource, you MUST also add a corresponding InfraMachineTemplate resources in order to use it when defining set of machines, e.g. MachineDeployments.
The template resource MUST be named as <InfraMachine>Template.
// +kubebuilder:object:root=true
// +kubebuilder:resource:path=foomachinetemplates,scope=Namespaced,categories=cluster-api
// +kubebuilder:storageversion
// FooMachineTemplate is the Schema for the foomachinetemplates API.
type FooMachineTemplate struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec FooMachineTemplateSpec `json:"spec,omitempty"`
}
type FooMachineTemplateSpec struct {
Template FooMachineTemplateResource `json:"template"`
}
type FooMachineTemplateResource struct {
// Standard object's metadata.
// More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata
// +optional
ObjectMeta clusterv1.ObjectMeta `json:"metadata,omitempty,omitzero"`
Spec FooMachineSpec `json:"spec"`
}
NOTE: in this example InfraMachineTemplate’s spec.template.spec embeds FooMachineSpec from InfraMachine. This might not always be
the best choice depending of if/how InfraMachine’s spec fields applies to many machines vs only one.
For each InfraMachineTemplate resource, you MUST also add the corresponding list resource.
The list resource MUST be named as <InfraMachineTemplate>List.
// +kubebuilder:object:root=true
// FooMachineTemplateList contains a list of FooMachineTemplates.
type FooMachineTemplateList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []FooMachineTemplate `json:"items"`
}
InfraMachineTemplate: support for SSA dry run
When Cluster API’s topology controller is trying to identify differences between templates defined in a ClusterClass and the current Cluster topology, it is required to run Server Side Apply (SSA) dry run call.
However, in case you immutability checks for your InfraMachineTemplate, this can lead the SSA dry run call to errors.
In order to avoid this InfraMachineTemplate MUST specifically implement support for SSA dry run calls from the topology controller.
The implementation requires to use controller runtime’s CustomValidator, available in CR versions >= v0.12.3.
This will allow to skip the immutability check only when the topology controller is dry running while preserving the validation behavior for all other cases.
See the DockerMachineTemplate webhook as a reference for a compatible implementation.
Multi tenancy
Multi tenancy in Cluster API defines the capability of an infrastructure provider to manage different credentials, each one of them corresponding to an infrastructure tenant.
See infrastructure Provider Security Guidance for considerations about cloud provider credential management.
Please also note that Cluster API does not support running multiples instances of the same provider, which someone can assume an alternative solution to implement multi tenancy; same applies to the clusterctl CLI.
See Support running multiple instances of the same provider for more context.
However, if you want to make it possible for users to run multiples instances of your provider, your controller’s SHOULD:
- support the
--namespaceflag. - support the
--watch-filterflag.
Please, read carefully the page linked above to fully understand implications and risks related to this option.
Clusterctl support
The clusterctl command is designed to work with all the providers compliant with the rules defined in the clusterctl provider contract.
InfraMachine: pausing
Providers SHOULD implement the pause behaviour for every object with a reconciliation loop. This is done by checking if spec.paused is set on the Cluster object and by checking for the cluster.x-k8s.io/paused annotation on the InfraMachine object.
If implementing the pause behavior, providers SHOULD surface the paused status of an object using the Paused condition: Status.Conditions[Paused].
InfraMachineTemplate: support cluster autoscaling from zero
As described in the enhancement Opt-in Autoscaling from Zero, providers may implement the capacity and nodeInfo fields in machine templates to inform the cluster autoscaler about the resources available on that machine type, the architecture, and the operating system it runs.
Building on the FooMachineTemplate example from above, this shows the addition of a status and capacity field:
import corev1 "k8s.io/api/core/v1"
// FooMachineTemplate is the Schema for the foomachinetemplates API.
type FooMachineTemplate struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec FooMachineTemplateSpec `json:"spec,omitempty"`
Status FooMachineTemplateStatus `json:"status,omitempty"`
}
// FooMachineTemplateStatus defines the observed state of FooMachineTemplate.
type FooMachineTemplateStatus struct {
// Capacity defines the resource capacity for this machine.
// This value is used for autoscaling from zero operations as defined in:
// https://github.com/kubernetes-sigs/cluster-api/blob/main/docs/proposals/20210310-opt-in-autoscaling-from-zero.md
// +optional
Capacity corev1.ResourceList `json:"capacity,omitempty"`
// +optional
NodeInfo NodeInfo `json:"nodeInfo,omitempty,omitzero"`
}
// Architecture represents the CPU architecture of the node.
// Its underlying type is a string and its value can be any of amd64, arm64, s390x, ppc64le.
// +kubebuilder:validation:Enum=amd64;arm64;s390x;ppc64le
// +enum
type Architecture string
// Example architecture constants defined for better readability and maintainability.
const (
ArchitectureAmd64 Architecture = "amd64"
ArchitectureArm64 Architecture = "arm64"
ArchitectureS390x Architecture = "s390x"
ArchitecturePpc64le Architecture = "ppc64le"
)
// NodeInfo contains information about the node's architecture and operating system.
// +kubebuilder:validation:MinProperties=1
type NodeInfo struct {
// architecture is the CPU architecture of the node.
// Its underlying type is a string and its value can be any of amd64, arm64, s390x, ppc64le.
// +optional
Architecture Architecture `json:"architecture,omitempty"`
// operatingSystem is a string representing the operating system of the node.
// This may be a string like 'linux' or 'windows'.
// +optional
OperatingSystem string `json:"operatingSystem,omitempty"`
}
When rendered to a manifest, the machine template status capacity field representing an amd64 linux instance with 500 megabytes of RAM, 1 CPU core, and 1 NVidia GPU should look like this:
status:
capacity:
memory: 500mb
cpu: "1"
nvidia.com/gpu: "1"
nodeInfo:
architecture: amd64
operatingSystem: linux
If the information in the nodeInfo field is not available, the result of the autoscaling from zero operation will depend
on the cluster autoscaler implementation. For example, the Cluster API implementation of the Kubernetes Cluster Autoscaler
will assume the host is running either the architecture set in the CAPI_SCALE_ZERO_DEFAULT_ARCH environment variable of
the cluster autoscaler pod environment, or the amd64 architecture and Linux operating system as default values.
See autoscaling.
Typical InfraMachine reconciliation workflow
A machine infrastructure provider must respond to changes to its InfraMachine resources. This process is typically called reconciliation. The provider must watch for new, updated, and deleted resources and respond accordingly.
As a reference you can look at the following workflow to understand how the typical reconciliation workflow is implemented in InfraMachine controllers:
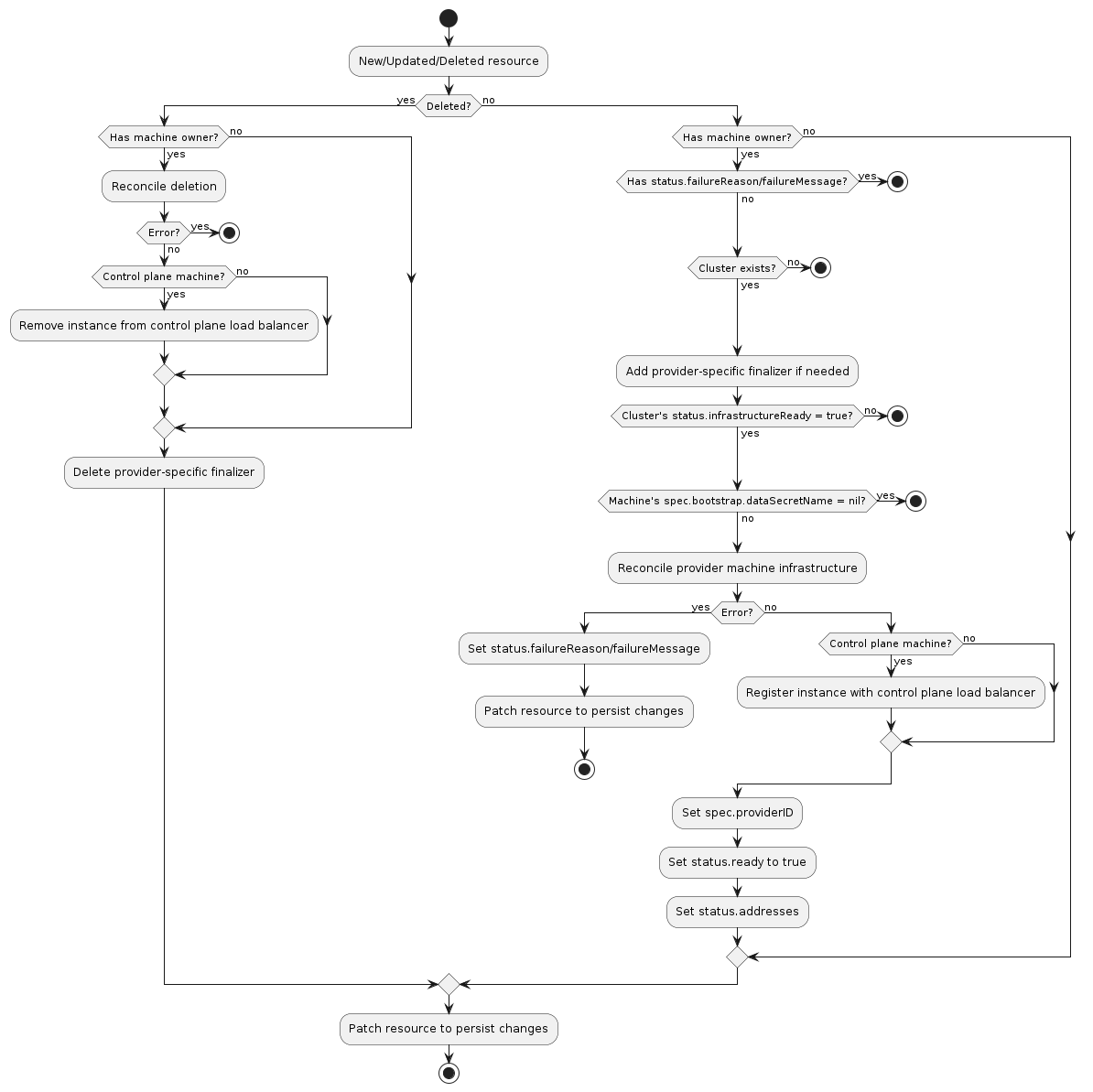
Normal resource
- If the resource does not have a
Machineowner, exit the reconciliation- The Cluster API
Machinereconciler populates this based on the value in theMachines‘sspec.infrastructureReffield
- The Cluster API
- If the
Clusterto which this resource belongs cannot be found, exit the reconciliation - Add the provider-specific finalizer, if needed
- If the associated
Cluster‘sstatus.infrastructureReadyisfalse, exit the reconciliation- Note: This check should not be blocking any further delete reconciliation flows.
- Note: This check should only be performed after appropriate owner references (if any) are updated.
- If the associated
Machine‘sspec.bootstrap.dataSecretNameisnil, exit the reconciliation - Reconcile provider-specific machine infrastructure
- If this is a control plane machine, register the instance with the provider’s control plane load balancer (optional)
- Set
spec.providerIDto the provider-specific identifier for the provider’s machine instance - Set
status.infrastructure.provisionedtotrue - Set
status.addressesto the provider-specific set of instance addresses (optional) - Set
status.failureDomainto the provider-specific failure domain the instance is running in (optional) - Patch the resource to persist changes
Deleted resource
- If the resource has a
Machineowner- Perform deletion of provider-specific machine infrastructure
- If this is a control plane machine, deregister the instance from the provider’s control plane load balancer (optional)
- If any errors are encountered, exit the reconciliation
- Remove the provider-specific finalizer from the resource
- Patch the resource to persist changes