Machine Infrastructure Provider Specification
Overview
A machine infrastructure provider is responsible for managing the lifecycle of provider-specific machine instances. These may be physical or virtual instances, and they represent the infrastructure for Kubernetes nodes.
Data Types
A machine infrastructure provider must define an API type for “infrastructure machine” resources. The type:
- Must belong to an API group served by the Kubernetes apiserver
- Must be implemented as a CustomResourceDefinition.
- The CRD name must have the format produced by
sigs.k8s.io/cluster-api/util/contract.CalculateCRDName(Group, Kind).
- The CRD name must have the format produced by
- Must be namespace-scoped
- Must have the standard Kubernetes “type metadata” and “object metadata”
- Must have a
specfield with the following:-
Required fields:
providerID(string): the identifier for the provider’s machine instance. This field is expected to match the value set by the KCM cloud provider in the Nodes. The Machine controller bubbles it up to the Machine CR, and it’s used to find the matching Node. Any other consumers can use the providerID as the source of truth to match both Machines and Nodes.
-
Optional fields:
failureDomain(string): the string identifier of the failure domain the instance is running in for the purposes of backwards compatibility and migrating to the v1alpha3 FailureDomain support (where FailureDomain is specified in Machine.Spec.FailureDomain). This field is meant to be temporary to aid in migration of data that was previously defined on the provider type and providers will be expected to remove the field in the next version that provides breaking API changes, favoring the value defined on Machine.Spec.FailureDomain instead. If supporting conversions from previous types, the provider will need to support a conversion from the provider-specific field that was previously used to thefailureDomainfield to support the automated migration path.
-
- Must have a
statusfield with the following:- Required fields:
ready(boolean): indicates the provider-specific infrastructure has been provisioned and is ready
- Optional fields:
failureReason(string): indicates there is a fatal problem reconciling the provider’s infrastructure; meant to be suitable for programmatic interpretationfailureMessage(string): indicates there is a fatal problem reconciling the provider’s infrastructure; meant to be a more descriptive value thanfailureReasonaddresses(MachineAddresses): a list of the host names, external IP addresses, internal IP addresses, external DNS names, and/or internal DNS names for the provider’s machine instance.MachineAddressis defined as:type(string): one ofHostname,ExternalIP,InternalIP,ExternalDNS,InternalDNSaddress(string)
- Required fields:
- Should have a conditions field with the following:
- A Ready condition to represent the overall operational state of the component. It can be based on the summary of more detailed conditions existing on the same object, e.g. instanceReady, SecurityGroupsReady conditions.
Note: once any of failureReason or failureMessage surface on the machine who is referencing the infrastructureMachine object,
they cannot be restored anymore (it is considered a terminal error; the only way to recover is to delete and recreate the machine).
Also, if the machine is under control of a MachineHealthCheck instance, the machine will be automatically remediated.
InfraMachineTemplate Resources
For a given InfraMachine resource, you should also add a corresponding InfraMachineTemplate resource:
// InfraMachineTemplateSpec defines the desired state of InfraMachineTemplate.
type InfraMachineTemplateSpec struct {
Template InfraMachineTemplateResource `json:"template"`
}
// +kubebuilder:object:root=true
// +kubebuilder:resource:path=inframachinetemplates,scope=Namespaced,categories=cluster-api,shortName=imt
// +kubebuilder:storageversion
// InfraMachineTemplate is the Schema for the inframachinetemplates API.
type InfraMachineTemplate struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec InfraMachineTemplateSpec `json:"spec,omitempty"`
}
type InfraMachineTemplateResource struct {
// Standard object's metadata.
// More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata
// +optional
ObjectMeta clusterv1.ObjectMeta `json:"metadata,omitempty"`
Spec InfraMachineSpec `json:"spec"`
}
The CRD name of the template must also have the format produced by sigs.k8s.io/cluster-api/util/contract.CalculateCRDName(Group, Kind).
List Resources
For any resource, also add list resources, e.g.
//+kubebuilder:object:root=true
// InfraMachineList contains a list of InfraMachines.
type InfraMachineList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []InfraCluster `json:"items"`
}
//+kubebuilder:object:root=true
// InfraMachineTemplateList contains a list of InfraMachineTemplates.
type InfraMachineTemplateList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []InfraClusterTemplate `json:"items"`
}
Behavior
A machine infrastructure provider must respond to changes to its “infrastructure machine” resources. This process is typically called reconciliation. The provider must watch for new, updated, and deleted resources and respond accordingly.
The following diagram shows the typical logic for a machine infrastructure provider:
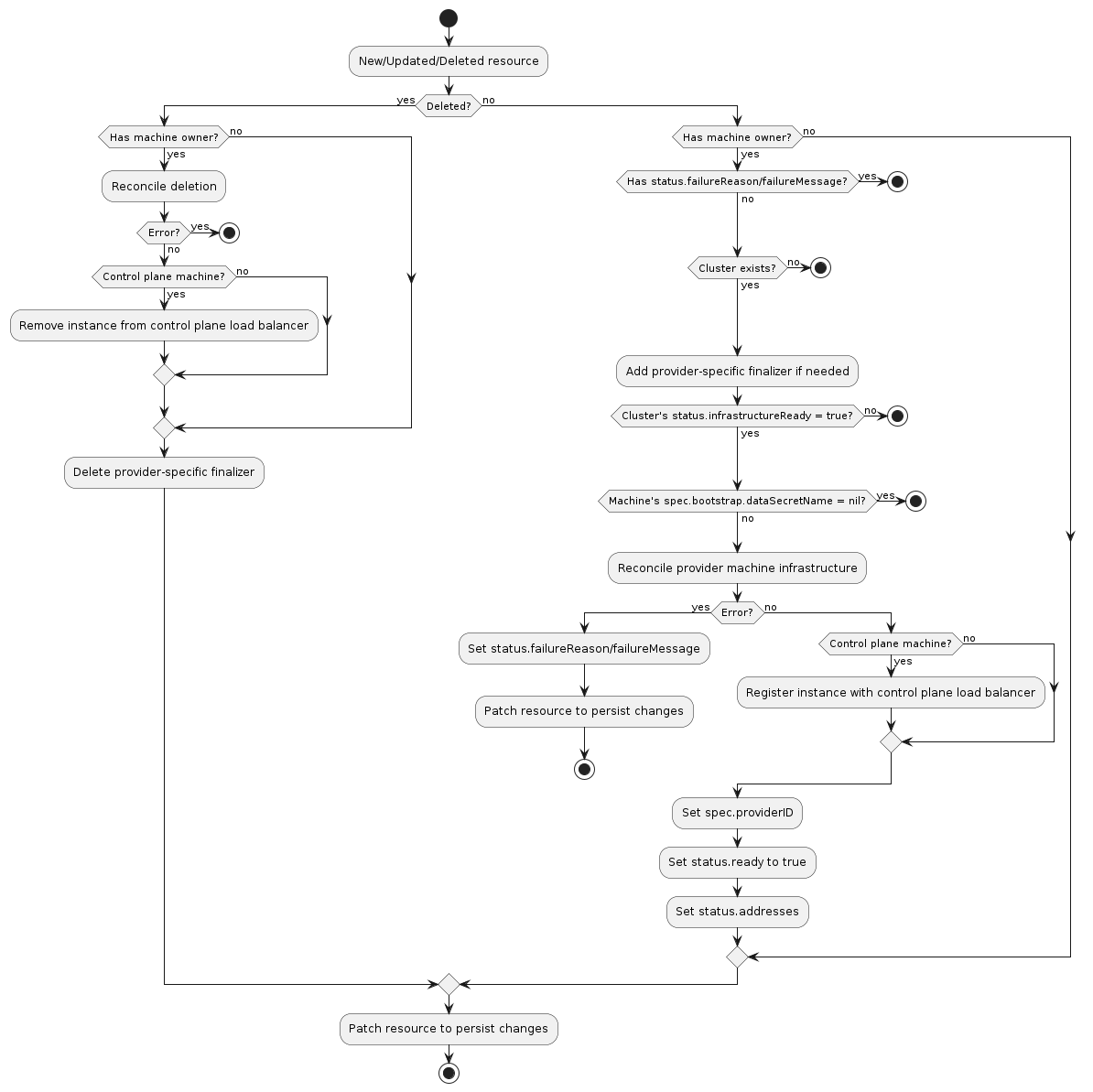
Normal resource
- If the resource does not have a
Machineowner, exit the reconciliation- The Cluster API
Machinereconciler populates this based on the value in theMachines‘sspec.infrastructureReffield
- The Cluster API
- If the resource has
status.failureReasonorstatus.failureMessageset, exit the reconciliation - If the
Clusterto which this resource belongs cannot be found, exit the reconciliation - Add the provider-specific finalizer, if needed
- If the associated
Cluster‘sstatus.infrastructureReadyisfalse, exit the reconciliation- Note: This check should not be blocking any further delete reconciliation flows.
- Note: This check should only be performed after appropriate owner references (if any) are updated.
- If the associated
Machine‘sspec.bootstrap.dataSecretNameisnil, exit the reconciliation - Reconcile provider-specific machine infrastructure
- If any errors are encountered:
- If they are terminal failures, set
status.failureReasonandstatus.failureMessage - Exit the reconciliation
- If they are terminal failures, set
- If this is a control plane machine, register the instance with the provider’s control plane load balancer (optional)
- If any errors are encountered:
- Set
spec.providerIDto the provider-specific identifier for the provider’s machine instance - Set
status.readytotrue - Set
status.addressesto the provider-specific set of instance addresses (optional) - Set
spec.failureDomainto the provider-specific failure domain the instance is running in (optional) - Patch the resource to persist changes
Deleted resource
- If the resource has a
Machineowner- Perform deletion of provider-specific machine infrastructure
- If this is a control plane machine, deregister the instance from the provider’s control plane load balancer (optional)
- If any errors are encountered, exit the reconciliation
- Remove the provider-specific finalizer from the resource
- Patch the resource to persist changes
RBAC
Provider controller
A machine infrastructure provider must have RBAC permissions for the types it defines. If you are using kubebuilder to
generate new API types, these permissions should be configured for you automatically. For example, the AWS provider has
the following configuration for its AWSMachine type:
// +kubebuilder:rbac:groups=infrastructure.cluster.x-k8s.io,resources=awsmachines,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=infrastructure.cluster.x-k8s.io,resources=awsmachines/status,verbs=get;update;patch
A machine infrastructure provider may also need RBAC permissions for other types, such as Cluster and Machine. If
you need read-only access, you can limit the permissions to get, list, and watch. You can use the following
configuration for retrieving Cluster and Machine resources:
// +kubebuilder:rbac:groups=cluster.x-k8s.io,resources=clusters;clusters/status,verbs=get;list;watch
// +kubebuilder:rbac:groups=cluster.x-k8s.io,resources=machines;machines/status,verbs=get;list;watch
Cluster API controllers
The Cluster API controller for Machine resources is configured with full read/write RBAC
permissions for all resources in the infrastructure.cluster.x-k8s.io API group. This group
represents all machine infrastructure providers for SIG Cluster Lifecycle-sponsored provider
subprojects. If you are writing a provider not sponsored by the SIG, you must grant full read/write
RBAC permissions for the “infrastructure machine” resource in your API group to the Cluster API
manager’s ServiceAccount. ClusterRoles can be granted using the aggregation label
cluster.x-k8s.io/aggregate-to-manager: "true". The following is an example ClusterRole for a
FooMachine resource:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: capi-foo-machines
labels:
cluster.x-k8s.io/aggregate-to-manager: "true"
rules:
- apiGroups:
- infrastructure.foo.com
resources:
- foomachines
verbs:
- create
- delete
- get
- list
- patch
- update
- watch
Note, the write permissions allow the Machine controller to set owner references and labels on the
“infrastructure machine” resources; they are not used for general mutations of these resources.