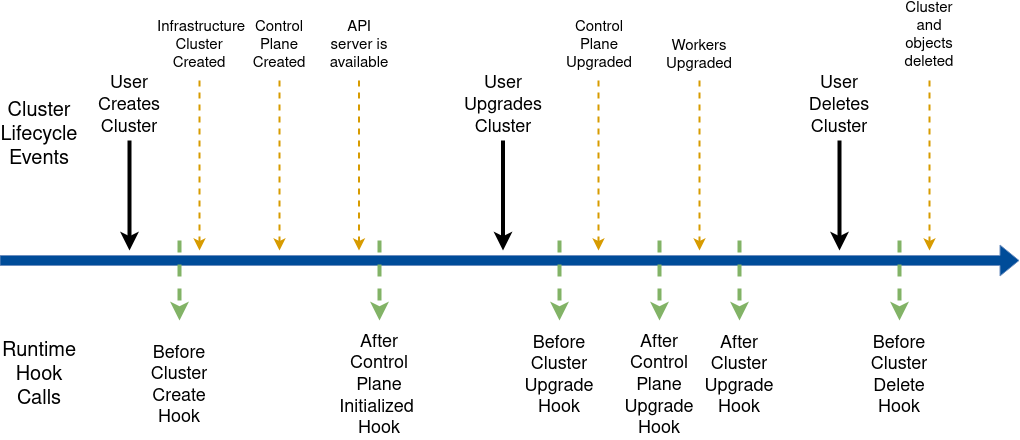
Cluster API is a Kubernetes sub-project focused on providing declarative APIs and tooling to simplify provisioning, upgrading, and operating multiple Kubernetes clusters.
Started by the Kubernetes Special Interest Group (SIG) Cluster Lifecycle, the Cluster API project uses Kubernetes-style APIs and patterns to automate cluster lifecycle management for platform operators. The supporting infrastructure, like virtual machines, networks, load balancers, and VPCs, as well as the Kubernetes cluster configuration are all defined in the same way that application developers operate deploying and managing their workloads. This enables consistent and repeatable cluster deployments across a wide variety of infrastructure environments.
Kubernetes is a complex system that relies on several components being configured correctly to have a working cluster. Recognizing this as a potential stumbling block for users, the community focused on simplifying the bootstrapping process. Today, over 100 Kubernetes distributions and installers have been created, each with different default configurations for clusters and supported infrastructure providers. SIG Cluster Lifecycle saw a need for a single tool to address a set of common overlapping installation concerns and started kubeadm.
Kubeadm was designed as a focused tool for bootstrapping a best-practices Kubernetes cluster. The core tenet behind the kubeadm project was to create a tool that other installers can leverage and ultimately alleviate the amount of configuration that an individual installer needed to maintain. Since it began, kubeadm has become the underlying bootstrapping tool for several other applications, including Kubespray, minikube, kind, etc.
However, while kubeadm and other bootstrap providers reduce installation complexity, they don’t address how to manage a cluster day-to-day or a Kubernetes environment long term. You are still faced with several questions when setting up a production environment, including:
How can I consistently provision machines, load balancers, VPC, etc., across multiple infrastructure providers and locations?
How can I automate cluster lifecycle management, including things like upgrades and cluster deletion?
How can I scale these processes to manage any number of clusters?
SIG Cluster Lifecycle began the Cluster API project as a way to address these gaps by building declarative, Kubernetes-style APIs, that automate cluster creation, configuration, and management. Using this model, Cluster API can also be extended to support any infrastructure provider (AWS, Azure, vSphere, etc.) or bootstrap provider (kubeadm is default) you need. See the growing list of available providers.
To manage the lifecycle (create, scale, upgrade, destroy) of Kubernetes-conformant clusters using a declarative API.
To work in different environments, both on-premises and in the cloud.
To define common operations, provide a default implementation, and provide the ability to swap out implementations for alternative ones.
To reuse and integrate existing ecosystem components rather than duplicating their functionality (e.g. node-problem-detector, cluster autoscaler, SIG-Multi-cluster).
To provide a transition path for Kubernetes lifecycle products to adopt Cluster API incrementally. Specifically, existing cluster lifecycle management tools should be able to adopt Cluster API in a staged manner, over the course of multiple releases, or even adopting a subset of Cluster API.
To add these APIs to Kubernetes core (kubernetes/kubernetes).
This API should live in a namespace outside the core and follow the best practices defined by api-reviewers, but is not subject to core-api constraints.
To manage the lifecycle of infrastructure unrelated to the running of Kubernetes-conformant clusters.
To force all Kubernetes lifecycle products (kOps, Kubespray, GKE, AKS, EKS, IKS etc.) to support or use these APIs.
To manage non-Cluster API provisioned Kubernetes-conformant clusters.
To manage a single cluster spanning multiple infrastructure providers.
To configure a machine at any time other than create or upgrade.
To duplicate functionality that exists or is coming to other tooling, e.g., updating kubelet configuration (c.f. dynamic kubelet configuration), or updating apiserver, controller-manager, scheduler configuration (c.f. component-config effort) after the cluster is deployed.
Cluster API is developed in the open, and is constantly being improved by our users, contributors, and maintainers. It is because of you that we are able to automate cluster lifecycle management for the community. Join us!
If you have questions or want to get the latest project news, you can connect with us in the following ways:
Pull Requests and feedback on issues are very welcome!
See the issue tracker if you’re unsure where to start, especially the Good first issue and Help wanted tags, and
also feel free to reach out to discuss.
There are two major quickstart paths: Using clusterctl or the Cluster API Operator.
This article describes a path that uses the clusterctl CLI tool to handle the lifecycle of a Cluster API management cluster.
The clusterctl command line interface is specifically designed for providing a simple “day 1 experience” and a quick start with Cluster API. It automates fetching the YAML files defining provider components and installing them.
Additionally it encodes a set of best practices in managing providers, that helps the user in avoiding mis-configurations or in managing day 2 operations such as upgrades.
The Cluster API Operator is a Kubernetes Operator built on top of clusterctl and designed to empower cluster administrators to handle the lifecycle of Cluster API providers within a management cluster using a declarative approach. It aims to improve user experience in deploying and managing Cluster API, making it easier to handle day-to-day tasks and automate workflows with GitOps. Visit the CAPI Operator quickstart if you want to experiment with this tool.
Cluster API requires an existing Kubernetes cluster accessible via kubectl. During the installation process the
Kubernetes cluster will be transformed into a management cluster by installing the Cluster API provider components, so it
is recommended to keep it separated from any application workload.
It is a common practice to create a temporary, local bootstrap cluster which is then used to provision
a target management cluster on the selected infrastructure provider.
Choose one of the options below:
Existing Management Cluster
For production use-cases a “real” Kubernetes cluster should be used with appropriate backup and disaster recovery policies and procedures in place. The Kubernetes cluster must be at least v1.20.0.
export KUBECONFIG=<...>
OR
Kind
kind can be used for creating a local Kubernetes cluster for development environments or for
the creation of a temporary bootstrap cluster used to provision a target management cluster on the selected infrastructure provider.
The installation procedure depends on the version of kind; if you are planning to use the Docker infrastructure provider,
please follow the additional instructions in the dedicated tab:
Create the kind cluster:
kind create cluster
Test to ensure the local kind cluster is ready:
kubectl cluster-info
Run the following command to create a kind config file for allowing the Docker provider to access Docker on the host:
Then follow the instruction for your kind version using kind create cluster --config kind-cluster-with-extramounts.yaml
to create the management cluster using the above file.
KubeVirt is a cloud native virtualization solution. The virtual machines we’re going to create and use for
the workload cluster’s nodes, are actually running within pods in the management cluster. In order to communicate with
the workload cluster’s API server, we’ll need to expose it. We are using Kind which is a limited environment. The
easiest way to expose the workload cluster’s API server (a pod within a node running in a VM that is itself running
within a pod in the management cluster, that is running inside a Docker container), is to use a LoadBalancer service.
To allow using a LoadBalancer service, we can’t use the kind’s default CNI (kindnet), but we’ll need to install
another CNI, like Calico. In order to do that, we’ll need first to initiate the kind cluster with two modifications:
Disable the default CNI
Add the Docker credentials to the cluster, to avoid the Docker Hub pull rate limit of the calico images; read more
about it in the docker documentation, and in the
kind documentation.
Create a configuration file for kind. Please notice the Docker config file path, and adjust it to your local setting:
cat <<EOF > kind-config.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
networking:
# the default CNI will not be installed
disableDefaultCNI: true
nodes:
- role: control-plane
extraMounts:
- containerPath: /var/lib/kubelet/config.json
hostPath: <YOUR DOCKER CONFIG FILE PATH>
EOF
Now, create the kind cluster with the configuration file:
Now we’ll need to install a CNI. In this example, we’re using calico, but other CNIs should work as well. Please see
calico installation guide
for more details (use the “Manifest” tab). Below is an example of how to install calico version v3.29.1.
Use the Calico manifest to create the required resources; e.g.:
Now that we’ve got clusterctl installed and all the prerequisites in place, let’s transform the Kubernetes cluster
into a management cluster by using clusterctl init.
The command accepts as input a list of providers to install; when executed for the first time, clusterctl init
automatically adds to the list the cluster-api core provider, and if unspecified, it also adds the kubeadm bootstrap
and kubeadm control-plane providers.
Feature gates can be enabled by exporting environment variables before executing clusterctl init.
For example, the ClusterTopology feature, which is required to enable support for managed topologies and ClusterClass,
can be enabled via:
export CLUSTER_TOPOLOGY=true
Additional documentation about experimental features can be found in Experimental Features.
Depending on the infrastructure provider you are planning to use, some additional prerequisites should be satisfied
before getting started with Cluster API. See below for the expected settings for common providers.
Move the binary to a directory present in your PATH
sudo mv clusterawsadm /usr/local/bin
Check version to confirm installation
clusterawsadm version
Example Usage
export AWS_REGION=us-east-1 # This is used to help encode your environment variables
export AWS_ACCESS_KEY_ID=<your-access-key>
export AWS_SECRET_ACCESS_KEY=<your-secret-access-key>
export AWS_SESSION_TOKEN=<session-token> # If you are using Multi-Factor Auth.
# The clusterawsadm utility takes the credentials that you set as environment
# variables and uses them to create a CloudFormation stack in your AWS account
# with the correct IAM resources.
clusterawsadm bootstrap iam create-cloudformation-stack
# Create the base64 encoded credentials using clusterawsadm.
# This command uses your environment variables and encodes
# them in a value to be stored in a Kubernetes Secret.
export AWS_B64ENCODED_CREDENTIALS=$(clusterawsadm bootstrap credentials encode-as-profile)
# Finally, initialize the management cluster
clusterctl init --infrastructure aws
Move the binary to a directory present in your PATH
sudo mv clusterawsadm /usr/local/bin
Check version to confirm installation
clusterawsadm version
Example Usage
export AWS_REGION=us-east-1 # This is used to help encode your environment variables
export AWS_ACCESS_KEY_ID=<your-access-key>
export AWS_SECRET_ACCESS_KEY=<your-secret-access-key>
export AWS_SESSION_TOKEN=<session-token> # If you are using Multi-Factor Auth.
# The clusterawsadm utility takes the credentials that you set as environment
# variables and uses them to create a CloudFormation stack in your AWS account
# with the correct IAM resources.
clusterawsadm bootstrap iam create-cloudformation-stack
# Create the base64 encoded credentials using clusterawsadm.
# This command uses your environment variables and encodes
# them in a value to be stored in a Kubernetes Secret.
export AWS_B64ENCODED_CREDENTIALS=$(clusterawsadm bootstrap credentials encode-as-profile)
# Finally, initialize the management cluster
clusterctl init --infrastructure aws
Install the latest release using homebrew:
brew install clusterawsadm
Check version to confirm installation
clusterawsadm version
Example Usage
export AWS_REGION=us-east-1 # This is used to help encode your environment variables
export AWS_ACCESS_KEY_ID=<your-access-key>
export AWS_SECRET_ACCESS_KEY=<your-secret-access-key>
export AWS_SESSION_TOKEN=<session-token> # If you are using Multi-Factor Auth.
# The clusterawsadm utility takes the credentials that you set as environment
# variables and uses them to create a CloudFormation stack in your AWS account
# with the correct IAM resources.
clusterawsadm bootstrap iam create-cloudformation-stack
# Create the base64 encoded credentials using clusterawsadm.
# This command uses your environment variables and encodes
# them in a value to be stored in a Kubernetes Secret.
export AWS_B64ENCODED_CREDENTIALS=$(clusterawsadm bootstrap credentials encode-as-profile)
# Finally, initialize the management cluster
clusterctl init --infrastructure aws
Append or prepend the path of that directory to the PATH environment variable.
Check version to confirm installation
clusterawsadm.exe version
Example Usage in Powershell
$Env:AWS_REGION="us-east-1" # This is used to help encode your environment variables
$Env:AWS_ACCESS_KEY_ID="<your-access-key>"
$Env:AWS_SECRET_ACCESS_KEY="<your-secret-access-key>"
$Env:AWS_SESSION_TOKEN="<session-token>" # If you are using Multi-Factor Auth.
# The clusterawsadm utility takes the credentials that you set as environment
# variables and uses them to create a CloudFormation stack in your AWS account
# with the correct IAM resources.
clusterawsadm bootstrap iam create-cloudformation-stack
# Create the base64 encoded credentials using clusterawsadm.
# This command uses your environment variables and encodes
# them in a value to be stored in a Kubernetes Secret.
$Env:AWS_B64ENCODED_CREDENTIALS=$(clusterawsadm bootstrap credentials encode-as-profile)
# Finally, initialize the management cluster
clusterctl init --infrastructure aws
For more information about authorization, AAD, or requirements for Azure, visit the Azure provider prerequisites document.
export AZURE_SUBSCRIPTION_ID="<SubscriptionId>"
# Create an Azure Service Principal and paste the output here
export AZURE_TENANT_ID="<Tenant>"
export AZURE_CLIENT_ID="<AppId>"
export AZURE_CLIENT_ID_USER_ASSIGNED_IDENTITY=$AZURE_CLIENT_ID # for compatibility with CAPZ v1.16 templates
export AZURE_CLIENT_SECRET="<Password>"
# Settings needed for AzureClusterIdentity used by the AzureCluster
export AZURE_CLUSTER_IDENTITY_SECRET_NAME="cluster-identity-secret"
export CLUSTER_IDENTITY_NAME="cluster-identity"
export AZURE_CLUSTER_IDENTITY_SECRET_NAMESPACE="default"
# Create a secret to include the password of the Service Principal identity created in Azure
# This secret will be referenced by the AzureClusterIdentity used by the AzureCluster
kubectl create secret generic "${AZURE_CLUSTER_IDENTITY_SECRET_NAME}" --from-literal=clientSecret="${AZURE_CLIENT_SECRET}" --namespace "${AZURE_CLUSTER_IDENTITY_SECRET_NAMESPACE}"
# Finally, initialize the management cluster
clusterctl init --infrastructure azure
Create a file named cloud-config in the repo’s root directory, substituting in your own environment’s values
Create the base64 encoded credentials by catting your credentials file.
This command uses your environment variables and encodes
them in a value to be stored in a Kubernetes Secret.
The Docker provider requires the ClusterTopology and MachinePool features to deploy ClusterClass-based clusters.
We are only supporting ClusterClass-based cluster-templates in this quickstart as ClusterClass makes it possible to
adapt configuration based on Kubernetes version. This is required to install Kubernetes clusters < v1.24 and
for the upgrade from v1.23 to v1.24 as we have to use different cgroupDrivers depending on Kubernetes version.
# Enable the experimental Cluster topology feature.
export CLUSTER_TOPOLOGY=true
# Initialize the management cluster
clusterctl init --infrastructure docker
In order to initialize the Equinix Metal Provider (formerly Packet) you have to expose the environment
variable PACKET_API_KEY. This variable is used to authorize the infrastructure
provider manager against the Equinix Metal API. You can retrieve your token directly
from the Equinix Metal Console.
# Create the base64 encoded credentials by catting your credentials json.
# This command uses your environment variables and encodes
# them in a value to be stored in a Kubernetes Secret.
export GCP_B64ENCODED_CREDENTIALS=$( cat /path/to/gcp-credentials.json | base64 | tr -d '\n' )
# Finally, initialize the management cluster
clusterctl init --infrastructure gcp
# Please ensure that the values for `CLOUD_SDK_AK` and `CLOUD_SDK_SK` are base64 encoded.
export CLOUD_SDK_AK=$( echo $AccessKey | base64 | tr -d '\n' )
export CLOUD_SDK_SK=$( echo $SecretKey | base64 | tr -d '\n' )
# Finally, initialize the management cluster
clusterctl init --infrastructure huawei
In order to initialize the IBM Cloud Provider you have to expose the environment
variable IBMCLOUD_API_KEY. This variable is used to authorize the infrastructure
provider manager against the IBM Cloud API. To create one from the UI, refer here.
As described above, we want to use a LoadBalancer service in order to expose the workload cluster’s API server. In the
example below, we will use MetalLB solution to implement load balancing to our kind
cluster. Other solution should work as well.
Now, we’ll create the IPAddressPool and the L2Advertisement custom resources. For that, we’ll need to set the IP
range. First, we’ll read the kind network in order to find its subnet:
The Proxmox credentials are optional, when creating a cluster they can be set in the ProxmoxCluster resource,
if you do not set them here.
# The host for the Proxmox cluster
export PROXMOX_URL="https://pve.example:8006"
# The Proxmox token ID to access the remote Proxmox endpoint
export PROXMOX_TOKEN='root@pam!capi'
# The secret associated with the token ID
# You may want to set this in `$XDG_CONFIG_HOME/cluster-api/clusterctl.yaml` so your password is not in
# bash history
export PROXMOX_SECRET="1234-1234-1234-1234"
# Finally, initialize the management cluster
clusterctl init --infrastructure proxmox --ipam in-cluster
For more information about the CAPI provider for Proxmox, see the Proxmox
project.
# Initialize the management cluster
clusterctl init --infrastructure virtink
# The username used to access the remote vSphere endpoint
export VSPHERE_USERNAME="vi-admin@vsphere.local"
# The password used to access the remote vSphere endpoint
# You may want to set this in `$XDG_CONFIG_HOME/cluster-api/clusterctl.yaml` so your password is not in
# bash history
export VSPHERE_PASSWORD="admin!23"
# Finally, initialize the management cluster
clusterctl init --infrastructure vsphere
For more information about prerequisites, credentials management, or permissions for vSphere, see the vSphere
project.
Fetching providers
Installing cert-manager Version="v1.11.0"
Waiting for cert-manager to be available...
Installing Provider="cluster-api" Version="v1.0.0" TargetNamespace="capi-system"
Installing Provider="bootstrap-kubeadm" Version="v1.0.0" TargetNamespace="capi-kubeadm-bootstrap-system"
Installing Provider="control-plane-kubeadm" Version="v1.0.0" TargetNamespace="capi-kubeadm-control-plane-system"
Installing Provider="infrastructure-docker" Version="v1.0.0" TargetNamespace="capd-system"
Your management cluster has been initialized successfully!
You can now create your first workload cluster by running the following:
clusterctl generate cluster [name] --kubernetes-version [version] | kubectl apply -f -
Depending on the infrastructure provider you are planning to use, some additional prerequisites should be satisfied
before configuring a cluster with Cluster API. Instructions are provided for common providers below.
Otherwise, you can look at the clusterctl generate clustercommand documentation for details about how to
discover the list of variables required by a cluster templates.
# Name of the Azure datacenter location. Change this value to your desired location.
export AZURE_LOCATION="centralus"
# Select VM types.
export AZURE_CONTROL_PLANE_MACHINE_TYPE="Standard_D2s_v3"
export AZURE_NODE_MACHINE_TYPE="Standard_D2s_v3"
# [Optional] Select resource group. The default value is ${CLUSTER_NAME}.
export AZURE_RESOURCE_GROUP="<ResourceGroupName>"
A Cluster API compatible image must be available in your CloudStack installation. For instructions on how to build a compatible image
see image-builder (CloudStack)
Apart from the script, the following CloudStack environment variables are required.
# Set this to the name of the zone in which to deploy the cluster
export CLOUDSTACK_ZONE_NAME=<zone name>
# The name of the network on which the VMs will reside
export CLOUDSTACK_NETWORK_NAME=<network name>
# The endpoint of the workload cluster
export CLUSTER_ENDPOINT_IP=<cluster endpoint address>
export CLUSTER_ENDPOINT_PORT=<cluster endpoint port>
# The service offering of the control plane nodes
export CLOUDSTACK_CONTROL_PLANE_MACHINE_OFFERING=<control plane service offering name>
# The service offering of the worker nodes
export CLOUDSTACK_WORKER_MACHINE_OFFERING=<worker node service offering name>
# The capi compatible template to use
export CLOUDSTACK_TEMPLATE_NAME=<template name>
# The ssh key to use to log into the nodes
export CLOUDSTACK_SSH_KEY_NAME=<ssh key name>
A full configuration reference can be found in configuration.md.
A ClusterAPI compatible image must be available in your DigitalOcean account. For instructions on how to build a compatible image
see image-builder.
The Docker provider does not require additional configurations for cluster templates.
However, if you require special network settings you can set the following environment variables:
# The list of service CIDR, default ["10.128.0.0/12"]
export SERVICE_CIDR=["10.96.0.0/12"]
# The list of pod CIDR, default ["192.168.0.0/16"]
export POD_CIDR=["192.168.0.0/16"]
# The service domain, default "cluster.local"
export SERVICE_DOMAIN="k8s.test"
It is also possible but not recommended to disable the per-default enabled Pod Security Standard:
export POD_SECURITY_STANDARD_ENABLED="false"
There are several required variables you need to set to create a cluster. There
are also a few optional tunables if you’d like to change the OS or CIDRs used.
# Required (made up examples shown)
# The project where your cluster will be placed to.
# You have to get one from the Equinix Metal Console if you don't have one already.
export PROJECT_ID="2b59569f-10d1-49a6-a000-c2fb95a959a1"
# This can help to take advantage of automated, interconnected bare metal across our global metros.
export METRO="da"
# What plan to use for your control plane nodes
export CONTROLPLANE_NODE_TYPE="m3.small.x86"
# What plan to use for your worker nodes
export WORKER_NODE_TYPE="m3.small.x86"
# The ssh key you would like to have access to the nodes
export SSH_KEY="ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIDvMgVEubPLztrvVKgNPnRe9sZSjAqaYj9nmCkgr4PdK username@computer"
export CLUSTER_NAME="my-cluster"
# Optional (defaults shown)
export NODE_OS="ubuntu_18_04"
export POD_CIDR="192.168.0.0/16"
export SERVICE_CIDR="172.26.0.0/16"
# Only relevant if using the kube-vip flavor
export KUBE_VIP_VERSION="v0.5.0"
# Name of the GCP datacenter location. Change this value to your desired location
export GCP_REGION="<GCP_REGION>"
export GCP_PROJECT="<GCP_PROJECT>"
# Make sure to use same Kubernetes version here as building the GCE image
export KUBERNETES_VERSION=1.23.3
# This is the image you built. See https://github.com/kubernetes-sigs/image-builder
export IMAGE_ID=projects/$GCP_PROJECT/global/images/<built image>
export GCP_CONTROL_PLANE_MACHINE_TYPE=n1-standard-2
export GCP_NODE_MACHINE_TYPE=n1-standard-2
export GCP_NETWORK_NAME=<GCP_NETWORK_NAME or default>
export CLUSTER_NAME="<CLUSTER_NAME>"
# Cloud Provider credentials, which are a Kubeconfig generated using this process: https://docs.harvesterhci.io/v1.3/rancher/cloud-provider/#deploying-to-the-rke2-custom-cluster-experimental
# Since v0.1.5, this can be left "", because the controller can update it automatically
export CLOUD_CONFIG_KUBECONFIG_B64=""
# Name of the CAPI Cluster
export CLUSTER_NAME="<CLUSTER_NAME>"
# Number of Control Plane machines
export CONTROL_PLANE_MACHINE_COUNT=3
# URL to access the Harvester Cluster, this will be overridden by the controller
export HARVESTER_ENDPOINT=""
# Base64-Encoded Kubeconfig to access Harvester, which can be downloaded from Harvester's UI or from a Harvester Manager Node.
export HARVESTER_KUBECONFIG_B64="<HARVESTER_KUBECONFIG_ENCODED_IN_BASE64>"
# Namespace for all resources in the Management Cluster
export NAMESPACE="test"
# Pod CIDR for the Workload Cluster, it should have the format: 192.168.0.0/16
export POD_CIDR="10.42.0.0/16"
# Service CIDR for the Workload Cluster, it should have the format : 192.168.0.0/16 and be different from POD_CIDR
export SERVICE_CIDR="10.43.0.0/16"
# Reference to SSH Keypair in Harvester. It should follow the format <NAMESPACE>/<NAME>
export SSH_KEYPAIR="default/ssk-key-pair"
# Namespace in Harvester where the VMs will be created.
export TARGET_HARVESTER_NAMESPACE="default"
# Disk Size to be used by the VMs
export VM_DISK_SIZE="50Gi"
# Reference to OS Image in Harvester which will be used for creating VMs, It must follow the format <NAMESPACE>/<NAME>
export VM_IMAGE_NAME="default/jammy-server"
# Reference to VM Network in Harvester. It must follow the format <NAMESPACE>/<NAME>
export VM_NETWORK="default/untagged"
# Linux Username for the VMs
export VM_SSH_USER="ubuntu"
# Number of Worker nodes in the target Workload cluster
export WORKER_MACHINE_COUNT=2
# huawei cloud region
export HC_REGION="cn-east-1"
# ECS SSH key name
export HC_SSH_KEY_NAME="default"
# kubernetes version
export KUBERNETES_VERSION="1.32.0"
# number of control plane machines
export CONTROL_PLANE_MACHINE_COUNT="1"
# number of worker machines
export WORKER_MACHINE_COUNT="1"
# control plane machine type
export HC_CONTROL_PLANE_MACHINE_TYPE="x1e.2u.4g"
# worker node machine type
export HC_NODE_MACHINE_TYPE="x1e.2u.4g"
# ECS image ID
export ECS_IMAGE_ID="218ca5t7-bxf3-5dg0-852p-y703c9fe1a52"
# Required environment variables for VPC
# VPC region
export IBMVPC_REGION=us-south
# VPC zone within the region
export IBMVPC_ZONE=us-south-1
# ID of the resource group in which the VPC will be created
export IBMVPC_RESOURCEGROUP=<your-resource-group-id>
# Name of the VPC
export IBMVPC_NAME=ibm-vpc-0
export IBMVPC_IMAGE_ID=<you-image-id>
# Profile for the virtual server instances
export IBMVPC_PROFILE=bx2-4x16
export IBMVPC_SSHKEY_ID=<your-sshkey-id>
# Required environment variables for PowerVS
export IBMPOWERVS_SSHKEY_NAME=<your-ssh-key>
# Internal and external IP of the network
export IBMPOWERVS_VIP=<internal-ip>
export IBMPOWERVS_VIP_EXTERNAL=<external-ip>
export IBMPOWERVS_VIP_CIDR=29
export IBMPOWERVS_IMAGE_NAME=<your-capi-image-name>
# ID of the PowerVS service instance
export IBMPOWERVS_SERVICE_INSTANCE_ID=<service-instance-id>
export IBMPOWERVS_NETWORK_NAME=<your-capi-network-name>
A ClusterAPI compatible image must be available in your IONOS Cloud contract.
For instructions on how to build a compatible Image, see our docs.
# The token which is used to authenticate against the IONOS Cloud API
export IONOS_TOKEN=<your-token>
# The datacenter ID where the cluster will be deployed
export IONOSCLOUD_DATACENTER_ID="<your-datacenter-id>"
# The IP of the control plane endpoint
export CONTROL_PLANE_ENDPOINT_IP=10.10.10.4
# The location of the data center where the cluster will be deployed
export CONTROL_PLANE_ENDPOINT_LOCATION=de/txl
# The image ID of the custom image that will be used for the VMs
export IONOSCLOUD_MACHINE_IMAGE_ID="<your-image-id>"
# The SSH key that will be used to access the VMs
export IONOSCLOUD_MACHINE_SSH_KEYS="<your-ssh-key>"
# Required environment variables
# The KKZONE is used to specify where to download the binaries. (e.g. "", "cn")
export KKZONE=""
# The ssh name of the all instance Linux user. (e.g. root, ubuntu)
export USER_NAME=<your-linux-user>
# The ssh password of the all instance Linux user.
export PASSWORD=<your-linux-user-password>
# The ssh IP address of the all instance. (e.g. "[{address: 192.168.100.3}, {address: 192.168.100.4}]")
export INSTANCES=<your-linux-ip-address>
# The cluster control plane VIP. (e.g. "192.168.100.100")
export CONTROL_PLANE_ENDPOINT_IP=<your-control-plane-virtual-ip>
Note: If you are running CAPM3 release prior to v0.5.0, make sure to export the following
environment variables. However, you don’t need them to be exported if you use
CAPM3 release v0.5.0 or higher.
# The URL of the kernel to deploy.
export DEPLOY_KERNEL_URL="http://172.22.0.1:6180/images/ironic-python-agent.kernel"
# The URL of the ramdisk to deploy.
export DEPLOY_RAMDISK_URL="http://172.22.0.1:6180/images/ironic-python-agent.initramfs"
# The URL of the Ironic endpoint.
export IRONIC_URL="http://172.22.0.1:6385/v1/"
# The URL of the Ironic inspector endpoint.
export IRONIC_INSPECTOR_URL="http://172.22.0.1:5050/v1/"
# Do not use a dedicated CA certificate for Ironic API. Any value provided in this variable disables additional CA certificate validation.
# To provide a CA certificate, leave this variable unset. If unset, then IRONIC_CA_CERT_B64 must be set.
export IRONIC_NO_CA_CERT=true
# Disables basic authentication for Ironic API. Any value provided in this variable disables authentication.
# To enable authentication, leave this variable unset. If unset, then IRONIC_USERNAME and IRONIC_PASSWORD must be set.
export IRONIC_NO_BASIC_AUTH=true
# Disables basic authentication for Ironic inspector API. Any value provided in this variable disables authentication.
# To enable authentication, leave this variable unset. If unset, then IRONIC_INSPECTOR_USERNAME and IRONIC_INSPECTOR_PASSWORD must be set.
export IRONIC_INSPECTOR_NO_BASIC_AUTH=true
# OpenNebula API endpoint and credentials
export ONE_XMLRPC='http://10.2.11.40:2633/RPC2'
export ONE_AUTH='oneadmin:opennebula'
# VM and VR templates to construct workload clusters from
export MACHINE_TEMPLATE_NAME='capone131'
export ROUTER_TEMPLATE_NAME='capone131-vr'
# VNs to deploy workload clusters into
export PUBLIC_NETWORK_NAME='service'
export PRIVATE_NETWORK_NAME='private'
# Name of the new workload cluster
export CLUSTER_NAME='one'
# Cloud-Provider image to deploy inside the new workload cluster
export CCM_IMG='ghcr.io/opennebula/cloud-provider-opennebula:latest'
# Initial size of the new workload cluster
export CONTROL_PLANE_MACHINE_COUNT='1'
export WORKER_MACHINE_COUNT='1'
A ClusterAPI compatible image must be available in your OpenStack. For instructions on how to build a compatible image
see image-builder.
Depending on your OpenStack and underlying hypervisor the following options might be of interest:
Apart from the script, the following OpenStack environment variables are required.
# The list of nameservers for OpenStack Subnet being created.
# Set this value when you need create a new network/subnet while the access through DNS is required.
export OPENSTACK_DNS_NAMESERVERS=<dns nameserver>
# FailureDomain is the failure domain the machine will be created in.
export OPENSTACK_FAILURE_DOMAIN=<availability zone name>
# The flavor reference for the flavor for your server instance.
export OPENSTACK_CONTROL_PLANE_MACHINE_FLAVOR=<flavor>
# The flavor reference for the flavor for your server instance.
export OPENSTACK_NODE_MACHINE_FLAVOR=<flavor>
# The name of the image to use for your server instance. If the RootVolume is specified, this will be ignored and use rootVolume directly.
export OPENSTACK_IMAGE_NAME=<image name>
# The SSH key pair name
export OPENSTACK_SSH_KEY_NAME=<ssh key pair name>
# The external network
export OPENSTACK_EXTERNAL_NETWORK_ID=<external network ID>
A full configuration reference can be found in configuration.md.
A ClusterAPI compatible image must be available in your Outscale account. For instructions on how to build a compatible image
see image-builder.
# The outscale root disk iops
export OSC_IOPS="<IOPS>"
# The outscale root disk size
export OSC_VOLUME_SIZE="<VOLUME_SIZE>"
# The outscale root disk volumeType
export OSC_VOLUME_TYPE="<VOLUME_TYPE>"
# The outscale key pair
export OSC_KEYPAIR_NAME="<KEYPAIR_NAME>"
# The outscale subregion name
export OSC_SUBREGION_NAME="<SUBREGION_NAME>"
# The outscale vm type
export OSC_VM_TYPE="<VM_TYPE>"
# The outscale image name
export OSC_IMAGE_NAME="<IMAGE_NAME>"
A ClusterAPI compatible image must be available in your Proxmox cluster. For instructions on how to build a compatible VM template
see image-builder.
# The node that hosts the VM template to be used to provision VMs
export PROXMOX_SOURCENODE="pve"
# The template VM ID used for cloning VMs
export TEMPLATE_VMID=100
# The ssh authorized keys used to ssh to the machines.
export VM_SSH_KEYS="ssh-ed25519 ..., ssh-ed25519 ..."
# The IP address used for the control plane endpoint
export CONTROL_PLANE_ENDPOINT_IP=10.10.10.4
# The IP ranges for Cluster nodes
export NODE_IP_RANGES="[10.10.10.5-10.10.10.50, 10.10.10.55-10.10.10.70]"
# The gateway for the machines network-config.
export GATEWAY="10.10.10.1"
# Subnet Mask in CIDR notation for your node IP ranges
export IP_PREFIX=24
# The Proxmox network device for VMs
export BRIDGE="vmbr1"
# The dns nameservers for the machines network-config.
export DNS_SERVERS="[8.8.8.8,8.8.4.4]"
# The Proxmox nodes used for VM deployments
export ALLOWED_NODES="[pve1,pve2,pve3]"
It is required to use an official CAPV machine images for your vSphere VM templates. See uploading CAPV machine images for instructions on how to do this.
# The vCenter server IP or FQDN
export VSPHERE_SERVER="10.0.0.1"
# The vSphere datacenter to deploy the management cluster on
export VSPHERE_DATACENTER="SDDC-Datacenter"
# The vSphere datastore to deploy the management cluster on
export VSPHERE_DATASTORE="vsanDatastore"
# The VM network to deploy the management cluster on
export VSPHERE_NETWORK="VM Network"
# The vSphere resource pool for your VMs
export VSPHERE_RESOURCE_POOL="*/Resources"
# The VM folder for your VMs. Set to "" to use the root vSphere folder
export VSPHERE_FOLDER="vm"
# The VM template to use for your VMs
export VSPHERE_TEMPLATE="ubuntu-1804-kube-v1.17.3"
# The public ssh authorized key on all machines
export VSPHERE_SSH_AUTHORIZED_KEY="ssh-rsa AAAAB3N..."
# The certificate thumbprint for the vCenter server
export VSPHERE_TLS_THUMBPRINT="97:48:03:8D:78:A9..."
# The storage policy to be used (optional). Set to "" if not required
export VSPHERE_STORAGE_POLICY="policy-one"
# The IP address used for the control plane endpoint
export CONTROL_PLANE_ENDPOINT_IP="1.2.3.4"
For more information about prerequisites, credentials management, or permissions for vSphere, see the vSphere getting started guide.
A Cluster API compatible image must be available in your Vultr account. For instructions on how to build a compatible image see image-builder for Vultr
As we described above, in this tutorial, we will use a LoadBalancer service in order to expose the API server of the
workload cluster, so we want to use the load balancer (lb) template (rather than the default one). We’ll use the
clusterctl’s --flavor flag for that:
When ready, run the following command to apply the cluster manifest.
kubectl apply -f capi-quickstart.yaml
The output is similar to this:
cluster.cluster.x-k8s.io/capi-quickstart created
dockercluster.infrastructure.cluster.x-k8s.io/capi-quickstart created
kubeadmcontrolplane.controlplane.cluster.x-k8s.io/capi-quickstart-control-plane created
dockermachinetemplate.infrastructure.cluster.x-k8s.io/capi-quickstart-control-plane created
machinedeployment.cluster.x-k8s.io/capi-quickstart-md-0 created
dockermachinetemplate.infrastructure.cluster.x-k8s.io/capi-quickstart-md-0 created
kubeadmconfigtemplate.bootstrap.cluster.x-k8s.io/capi-quickstart-md-0 created
The cluster will now start provisioning. You can check status with:
kubectl get cluster
You can also get an “at glance” view of the cluster and its resources by running:
clusterctl describe cluster capi-quickstart
and see an output similar to this:
NAME PHASE AGE VERSION
capi-quickstart Provisioned 8s v1.32.0
To verify the first control plane is up:
kubectl get kubeadmcontrolplane
You should see an output is similar to this:
NAME CLUSTER INITIALIZED API SERVER AVAILABLE REPLICAS READY UPDATED UNAVAILABLE AGE VERSION
capi-quickstart-g2trk capi-quickstart true 3 3 3 4m7s v1.32.0
After the first control plane node is up and running, we can retrieve the workload cluster Kubeconfig.
clusterctl get kubeconfig capi-quickstart > capi-quickstart.kubeconfig
For Docker Desktop on macOS, Linux or Windows use kind to retrieve the kubeconfig. Docker Engine for Linux works with the default clusterctl approach.
kind get kubeconfig --name capi-quickstart > capi-quickstart.kubeconfig
The Kubernetes in-tree cloud provider implementations are being removed in favor of external cloud providers (also referred to as “out-of-tree”). This requires deploying a new component called the cloud-controller-manager which is responsible for running all the cloud specific controllers that were previously run in the kube-controller-manager. To learn more, see this blog post.
Install the official cloud-provider-azure Helm chart on the workload cluster:
Next, create a Kubernetes secret using this configuration to securely store your cloud environment details.
You can create this secret for example with:
After a short while, our nodes should be running and in Ready state,
let’s check the status using kubectl get nodes:
kubectl --kubeconfig=./capi-quickstart.kubeconfig get nodes
NAME STATUS ROLES AGE VERSION
capi-quickstart-vs89t-gmbld Ready control-plane 5m33s v1.32.0
capi-quickstart-vs89t-kf9l5 Ready control-plane 6m20s v1.32.0
capi-quickstart-vs89t-t8cfn Ready control-plane 7m10s v1.32.0
capi-quickstart-md-0-55x6t-5649968bd7-8tq9v Ready <none> 6m5s v1.32.0
capi-quickstart-md-0-55x6t-5649968bd7-glnjd Ready <none> 6m9s v1.32.0
capi-quickstart-md-0-55x6t-5649968bd7-sfzp6 Ready <none> 6m9s v1.32.0
Calico not required for vcluster.
Before deploying the Calico CNI, make sure the VMs are running:
kubectl get vm
If our new VMs are running, we should see a response similar to this:
NAME AGE STATUS READY
capi-quickstart-control-plane-7s945 167m Running True
capi-quickstart-md-0-zht5j 164m Running True
We can also read the virtual machine instances:
kubectl get vmi
The output will be similar to:
NAME AGE PHASE IP NODENAME READY
capi-quickstart-control-plane-7s945 167m Running 10.244.82.16 kind-control-plane True
capi-quickstart-md-0-zht5j 164m Running 10.244.82.17 kind-control-plane True
Since our workload cluster is running within the kind cluster, we need to prevent conflicts between the kind
(management) cluster’s CNI, and the workload cluster CNI. The following modifications in the default Calico settings
are enough for these two CNI to work on (actually) the same environment.
Change the CIDR to a non-conflicting range
Change the value of the CLUSTER_TYPE environment variable to k8s
Change the value of the CALICO_IPV4POOL_IPIP environment variable to Never
Change the value of the CALICO_IPV4POOL_VXLAN environment variable to Always
Add the FELIX_VXLANPORT environment variable with the value of a non-conflicting port, e.g. "6789".
The following script downloads the Calico manifest and modifies the required field. The CIDR and the port values are examples.
This section provides a quickstart guide for using the Cluster API Operator to create a Kubernetes cluster.
To use the clusterctl quickstart path, visit this quickstart guide.
Instead of using environment variables as clusterctl does, Cluster API Operator uses Kubernetes secrets to store credentials for cloud providers. Refer to provider documentation on which credentials are required.
This example uses AWS provider, but the same approach can be used for other providers.
A Kubernetes cluster that manages the lifecycle of Workload Clusters. A Management Cluster is also where one or more providers run, and where resources such as Machines are stored.
A component responsible for the provisioning of infrastructure/computational resources required by the Cluster or by Machines (e.g. VMs, networking, etc.).
For example, cloud Infrastructure Providers include AWS, Azure, and Google, and bare metal Infrastructure Providers include VMware, MAAS, and metal3.io.
When there is more than one way to obtain resources from the same Infrastructure Provider (such as AWS offering both EC2 and EKS), each way is referred to as a variant.
The control plane is a set of components that serve the Kubernetes API and continuously reconcile desired state using control loops.
Self-provisioned: A Kubernetes control plane consisting of pods or machines wholly managed by a single Cluster API deployment.
e.g kubeadm uses static pods for running components such as kube-apiserver, kube-controller-manager and kube-scheduler
on control plane machines.
Pod-based deployments require an external hosting cluster. The control plane components are deployed using standard Deployment and StatefulSet objects and the API is exposed using a Service.
External or Managed control planes are offered and controlled by some system other than Cluster API, such as GKE, AKS, EKS, or IKS.
The default provider uses kubeadm to bootstrap the control plane. As of v1alpha3, it exposes the configuration via the KubeadmControlPlane object. The controller, capi-kubeadm-control-plane-controller-manager, can then create Machine and BootstrapConfig objects based on the requested replicas in the KubeadmControlPlane object.
A CustomResourceDefinition is a built-in resource that lets you extend the Kubernetes API. Each CustomResourceDefinition represents a customization of a Kubernetes installation. The Cluster API provides and relies on several CustomResourceDefinitions:
A “Machine” is the declarative spec for an infrastructure component hosting a Kubernetes Node (for example, a VM). If a new Machine object is created, a provider-specific controller will provision and install a new host to register as a new Node matching the Machine spec. If the Machine’s spec is updated, the controller replaces the host with a new one matching the updated spec. If a Machine object is deleted, its underlying infrastructure and corresponding Node will be deleted by the controller.
Common fields such as Kubernetes version are modeled as fields on the Machine’s spec. Any information that is provider-specific is part of the InfrastructureRef and is not portable between different providers.
From the perspective of Cluster API, all Machines are immutable: once they are created, they are never updated (except for labels, annotations and status), only deleted.
For this reason, MachineDeployments are preferable. MachineDeployments handle changes to machines by replacing them, in the same way core Deployments handle changes to Pod specifications.
A MachineDeployment provides declarative updates for Machines and MachineSets.
A MachineDeployment works similarly to a core Kubernetes Deployment. A MachineDeployment reconciles changes to a Machine spec by rolling out changes to 2 MachineSets, the old and the newly updated.
A MachineSet’s purpose is to maintain a stable set of Machines running at any given time.
A MachineSet works similarly to a core Kubernetes ReplicaSet. MachineSets are not meant to be used directly, but are the mechanism MachineDeployments use to reconcile desired state.
A MachineHealthCheck defines the conditions when a Node should be considered missing or unhealthy.
If the Node matches these unhealthy conditions for a given user-configured time, the MachineHealthCheck initiates remediation of the Node. Remediation of Nodes is performed by replacing the corresponding Machine.
MachineHealthChecks will only remediate Nodes if they are owned by a MachineSet. This ensures that the Kubernetes cluster does not lose capacity, since the MachineSet will create a new Machine to replace the failed Machine.
BootstrapData contains the Machine or Node role-specific initialization data (usually cloud-init) used by the Infrastructure Provider to bootstrap a Machine into a Node.
Taking inspiration from Tim Hockin’s talk at KubeCon NA 2023, also for the
Cluster API project is important to define the long term vision, the manifesto of “where we are going” and “why”.
This document would hopefully provide valuable context for all users, contributors and companies investing in this project,
as well as act as compass for all reviewers and maintainers currently working on it.
The Cluster API community is the foundation for this project’s past, present and future.
The project will continue to encourage and praise active participation and contribution.
We are an active part of a bigger ecosystem
The Cluster API community is an active part of Kubernetes SIG Cluster Lifecycle, of the broader Kubernetes community
and of the CNCF.
CNCF provides the core values this project recognizes and contributes to.
The Kubernetes community provides most of the practices and policies this project abides to or is inspired by.
The project remains true to its original goals and design principles:
Cluster API is a Kubernetes sub-project focused on providing declarative APIs and tooling to simplify provisioning,
upgrading, and operating multiple Kubernetes clusters.
Nowadays, like at the beginning of the project, some concepts from the above statement deserve further clarification.
The Cluster API project motto is “Kubernetes all the way down”, and this boils down to two elements.
The target state of a cluster can be defined using Kubernetes declarative APIs.
The project also implements controllers – Kubernetes reconcile loops – ensuring that desired and current state of the
cluster will remain consistent over time.
The combination of those elements, declarative APIs and controllers, defines “how” this project aims to make Kubernetes
and Cluster API a stable, reliable and consistent platform that just works to enable higher order business value
supported by cloud-native applications.
Kubernetes Cluster lifecycle management is a complex problem space, especially if you consider doing this across so
many different types of infrastructures.
Hiding this complexity behind a simple declarative API is “why” the Cluster API project ultimately exists.
The project is strongly committed to continue its quest in defining a set of common API primitives working consistently
across all infrastructures (one API to rule them all).
Working towards graduating our API to v1 will be the next step in this journey.
While doing so, the project should be inspired by Tim Hockin’s talk, and continue to move forward without increasing
operational and conceptual complexity for Cluster API’s users.
Like Kubernetes, also the Cluster API project claims the right to remain unfinished, because there is still a strong,
foundational need to continuously evolve, improve and adapt to the changing needs of Cluster API’s users and to the
growing Cloud Native ecosystem.
What is important to notice, is that being a project that is “continuously evolving” is not in contrast with another
request from Cluster API’s users, which is about the project being stable, as expected by a system that has “crossed the chasm”.
Those two requests from Cluster API’s users are two sides of the same coin, a reminder that Cluster API must
“evolve responsibly” by ensuring upgrade paths and avoiding (or at least minimizing) disruptions for users.
The Cluster API project will continue to “evolve responsibly” by abiding to the same guarantees that Kubernetes offers
for its own APIs, but also ensuring a continuous and obsessive focus on CI signal, test coverage and test flakes.
Also ensuring a predictable release calendar, clear support windows and compatibility matrix for each release
is a crucial part of this effort to “evolve responsibly”.
Tim Hockins explains the idea of complexity budget very well in his talk:
There is a finite amount of complexity that a project can absorb over a certain amount of time;
when the complexity budget runs out, bad things happen, quality decreases, we can’t fix bugs timely etc.
Since the beginning of the Cluster API project, its maintainers intuitively handled the complexity budget by following
this approach:
“We’ve got to say no to things today, so we can afford to do interesting things tomorrow”.
This is something that is never done lightly, and it is always the result of an open discussion considering the status
of the codebase, the status of the project CI signal, the complexity of the new feature etc. .
Being very pragmatic, also the resources committed to implement and to maintain a feature over time must be considered
when doing such an evaluation, because a model where everything falls on the shoulders of a small set of core
maintainers is not sustainable.
On the other side of this coin, Cluster API maintainer’s also claim the right to reconsider new ideas or ideas
previously put on hold whenever there are the conditions and the required community consensus to work on it.
Probably the most well-known case of this is about Cluster API maintainers repeatedly deferring on change requests
about nodes mutability in the initial phases of the project, while starting to embrace some mutable behavior in recent releases.
The Cluster API project is committed to keep working with the broader CAPI community – all the Cluster API providers –
as a single team in order to continuously improve and expand the capability of this solution.
As we learned the hard way, the extensibility model implemented by CAPI to support so many providers requires a
complementary effort to continuously explore new ways to offer a cohesive solution, not a bag of parts.
It is important to continue and renew efforts to make it easier to bootstrap and operate a system composed of many
components, to ensure consistent APIs and behaviors, to ensure quality across the board.
This effort lays its foundation in all the provider maintainers being committed to this goal, while the Cluster API project
will be the venue where common guidelines are discussed and documented, as well as the place of choice where common
components or utilities are developed and hosted.
Cluster API expects certificates and keys used for bootstrapping to follow the below convention. CABPK generates new certificates using this convention if they do not already exist.
Each certificate must be stored in a single secret named one of:
The certificates must also be labeled with the key-value pair cluster.x-k8s.io/cluster-name=[cluster name] (where [cluster name] is the name of the cluster it should be used with).
When using Kubeadm Control Plane provider (KCP) it is possible to configure automatic certificate rotations. KCP does this by triggering a rollout when the certificates on the control plane machines are about to expire.
If configured, the certificate rollout feature is available for all new and existing control plane machines.
To configure a rollout on the KCP machines you need to set .rolloutBefore.certificatesExpiryDays (minimum of 7 days).
Example:
apiVersion: controlplane.cluster.x-k8s.io/v1beta1
kind: KubeadmControlPlane
metadata:
name: example-control-plane
spec:
rolloutBefore:
certificatesExpiryDays: 21 # trigger a rollout if certificates expire within 21 days
kubeadmConfigSpec:
clusterConfiguration:
...
initConfiguration:
...
joinConfiguration:
...
machineTemplate:
infrastructureRef:
...
replicas: 1
version: v1.23.3
It is strongly recommended to set the certificatesExpiryDays to a large enough value so that all the machines will have time to complete rollout well in advance before the certificates expire.
KCP uses the value in the corresponding Control Plane machine’s Machine.Status.CertificatesExpiryDate to check if a machine’s certificates are going to expire and if it needs to be rolled out.
Machine.Status.CertificatesExpiryDate gets its value from one of the following 2 places:
machine.cluster.x-k8s.io/certificates-expiry annotation value on the Machine object. This annotation is not applied by default and it can be set by users to manually override the certificate expiry information.
machine.cluster.x-k8s.io/certificates-expiry annotation value on the Bootstrap Config object referenced by the machine. This value is automatically set for machines bootstrapped with CABPK that are owned by the KCP resource.
The annotation value is a RFC3339 format timestamp. The annotation value on the machine object, if provided, will take precedence.
Cluster API bootstrap provider Kubeadm (CABPK) is a component responsible for generating a cloud-init script to
turn a Machine into a Kubernetes Node. This implementation uses kubeadm
for Kubernetes bootstrap.
CABPK’s main responsibility is to convert a KubeadmConfig bootstrap object into a cloud-init script that is
going to turn a Machine into a Kubernetes Node using kubeadm.
The cloud-init script will be saved into a secret KubeadmConfig.Status.DataSecretName and then the infrastructure provider
(CAPD in this example) will pick up this value and proceed with the machine creation and the actual bootstrap.
The KubeadmConfig object allows full control of Kubeadm init/join operations by exposing raw InitConfiguration,
ClusterConfiguration and JoinConfiguration objects.
InitConfiguration and JoinConfiguration exposes Patches field which can be used to specify the patches from a directory,
this support is available from K8s 1.22 version onwards.
CABPK will fill in some values if they are left empty with sensible defaults:
KubeadmConfig field
Default
clusterConfiguration.KubernetesVersion
Machine.Spec.Version[1]
clusterConfiguration.clusterName
Cluster.metadata.name
clusterConfiguration.controlPlaneEndpoint
Cluster.status.apiEndpoints[0]
clusterConfiguration.networking.dnsDomain
Cluster.spec.clusterNetwork.serviceDomain
clusterConfiguration.networking.serviceSubnet
Cluster.spec.clusterNetwork.service.cidrBlocks[0]
clusterConfiguration.networking.podSubnet
Cluster.spec.clusterNetwork.pods.cidrBlocks[0]
joinConfiguration.discovery
a short lived BootstrapToken generated by CABPK
IMPORTANT! overriding above defaults could lead to broken Clusters.
[1] if both clusterConfiguration.KubernetesVersion and Machine.Spec.Version are empty, the latest Kubernetes
version will be installed (as defined by the default kubeadm behavior).
for KCP, InitConfiguration and ClusterConfiguration for the first control plane node; JoinConfiguration for additional control plane nodes
for machine deployments, JoinConfiguration for worker nodes
Bootstrap control plane node:
kind: KubeadmConfig
apiVersion: bootstrap.cluster.x-k8s.io/v1beta1
metadata:
name: my-control-plane1-config
spec:
initConfiguration:
nodeRegistration:
nodeRegistration: {} # node registration parameters are automatically injected by CAPD according to the kindest/node image in use.
Additional control plane nodes:
kind: KubeadmConfig
apiVersion: bootstrap.cluster.x-k8s.io/v1beta1
metadata:
name: my-control-plane2-config
spec:
joinConfiguration:
nodeRegistration:
nodeRegistration: {} # node registration parameters are automatically injected by CAPD according to the kindest/node image in use.
controlPlane: {}
worker nodes:
kind: KubeadmConfig
apiVersion: bootstrap.cluster.x-k8s.io/v1beta1
metadata:
name: my-worker1-config
spec:
joinConfiguration:
nodeRegistration:
nodeRegistration: {} # node registration parameters are automatically injected by CAPD according to the kindest/node image in use.
CABPK supports multiple control plane machines initing at the same time.
The generation of cloud-init scripts of different machines is orchestrated in order to ensure a cluster
bootstrap process that will be compliant with the correct Kubeadm init/join sequence. More in detail:
cloud-config-data generation starts only after Cluster.Status.InfrastructureReady flag is set to true.
at this stage, cloud-config-data will be generated for the first control plane machine only, keeping
on hold additional control plane machines existing in the cluster, if any (kubeadm init).
after the ControlPlaneInitialized conditions on the cluster object is set to true,
the cloud-config-data for all the other machines are generated (kubeadm join/join —control-plane).
The user can choose two approaches for certificate management:
provide required certificate authorities (CAs) to use for kubeadm init/kubeadm join --control-plane; such CAs
should be provided as a Secrets objects in the management cluster.
let KCP to generate the necessary Secrets objects with a self-signed certificate authority for kubeadm
See here for more info about certificate management with kubeadm.
The KubeadmConfig object supports customizing the content of the config-data. The following examples illustrate how to specify these options. They should be adapted to fit your environment and use case.
KubeadmConfig.Files specifies additional files to be created on the machine, either with content inline or by referencing a secret.
KubeadmConfig.Mounts specifies a list of mount points to be setup.
mounts:
- - LABEL=etcd_disk
- /var/lib/etcddisk
KubeadmConfig.Verbosity specifies the kubeadm log level verbosity
verbosity: 10
KubeadmConfig.UseExperimentalRetryJoin replaces a basic kubeadm command with a shell script with retries for joins. This will add about 40KB to userdata.
You can use KubeadmConfigSpec.files to put any files on nodes. This example puts a KubeletConfiguration file on nodes via KubeadmConfigSpec.files, and makes kubelet use it via KubeadmConfigSpec.kubeletExtraArgs. You can check available configurations of KubeletConfiguration on Kubelet Configuration (v1beta1) | Kubernetes.
This method is easy to replace the whole kubelet configuration generated by kubeadm, but it is not easy to replace only a part of the kubelet configuration.
We can pass kubelet command-line flags via KubeadmConfigSpec.kubeletExtraArgs. This example is equivalent to setting --kube-reserved, --system-reserved, and --eviction-hard flags for the kubelet command.
This method is useful when you want to set kubelet flags that are not configurable via the KubeletConfiguration file, however, it is not recommended to use this method to set flags that are configurable via the KubeletConfiguration file.
We can use kubeadm’s kubeletconfiguration patch target to patch the kubelet configuration file. In this example, we put a patch file for kubeletconfiguration target in strategicpatchtype on nodes via KubeadmConfigSpec.files. For more details, see Customizing components with the kubeadm API | Kubernetes
This method is useful when you want to change the kubelet configuration file partially on specific nodes. For example, you can deploy a partially patched kubelet configuration file on specific nodes based on the default configuration used for kubeadm init or kubeadm join.
apiVersion: controlplane.cluster.x-k8s.io/v1beta1
kind: KubeadmControlPlaneTemplate
metadata:
name: kubeadm-config-template-control-plane
namespace: default
spec:
template:
spec:
kubeadmConfigSpec:
files:
# Here we put a patch file for kubeletconfiguration target in strategic patchtype on nodes via KubeadmConfigSpec.files
# The naming convention of the patch file is kubeletconfiguration{suffix}+{patchtype}.json where {suffix} is an string and {patchtype} is one of the following: strategic, merge, json.
# {suffix} determines the order of the patch files. The patches are applied in the alpha-numerical order of the {suffix}.
- path: /etc/kubernetes/patches/kubeletconfiguration0+strategic.json
owner: "root:root"
permissions: "0644"
content: |
{
"apiVersion": "kubelet.config.k8s.io/v1beta1",
"kind": "KubeletConfiguration",
"kubeReserved": {
"cpu": "1",
"memory": "2Gi",
"ephemeral-storage": "1Gi",
},
"systemReserved": {
"cpu": "500m",
"memory": "1Gi",
"ephemeral-storage": "1Gi",
},
"evictionHard": {
"memory.available": "500Mi",
"nodefs.available": "10%",
},
}
initConfiguration:
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
# Here we specify the directory that contains the patch files
patches:
directory: /etc/kubernetes/patches
joinConfiguration:
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
# Here we specify the directory that contains the patch files
patches:
directory: /etc/kubernetes/patches
apiVersion: bootstrap.cluster.x-k8s.io/v1beta1
kind: KubeadmConfigTemplate
metadata:
name: kubeadm-config-template-default-worker-bootstraptemplate
namespace: default
spec:
template:
spec:
files:
# Here we put a patch file for kubeletconfiguration target in strategic patchtype on nodes via KubeadmConfigSpec.files
# The naming convention of the patch file is kubeletconfiguration{suffix}+{patchtype}.json where {suffix} is an string and {patchtype} is one of the following: strategic, merge, json.
# {suffix} determines the order of the patch files. The patches are applied in the alpha-numerical order of the {suffix}.
- path: /etc/kubernetes/patches/kubeletconfiguration0+strategic.json
owner: "root:root"
permissions: "0644"
content: |
{
"apiVersion": "kubelet.config.k8s.io/v1beta1",
"kind": "KubeletConfiguration",
"kubeReserved": {
"cpu": "1",
"memory": "2Gi",
"ephemeral-storage": "1Gi",
},
"systemReserved": {
"cpu": "500m",
"memory": "1Gi",
"ephemeral-storage": "1Gi",
},
"evictionHard": {
"memory.available": "500Mi",
"nodefs.available": "10%",
},
}
joinConfiguration:
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
# Here we specify the directory that contains the patch files
patches:
directory: /etc/kubernetes/patches
Cluster API bootstrap provider MicroK8s (CABPM) is a component responsible for generating a cloud-init script to turn a Machine into a Kubernetes Node. This implementation uses MicroK8s for Kubernetes bootstrap.
MicroK8s defines a MicroK8sControlPlane definition as well as the MachineDeployment to configure the control plane and worker nodes respectively. The MicroK8sControlPlane is linked in the cluster definition as shown in the following example:
In both the MicroK8sControlPlane and MicroK8sConfigTemplate you can set a MicroK8sConfig object. In the MicroK8sControlPlane case MicroK8sConfig is under MicroK8sConfig.spec.controlPlaneConfig whereas in MicroK8sConfigTemplate it is under MicroK8sConfigTemplate.spec.template.spec.
Some of the configuration options available via MicroK8sConfig are:
MicroK8sConfig.spec.initConfiguration.joinTokenTTLInSecs: the time-to-live (TTL) of the token used to join nodes, defaults to 10 years.
MicroK8sConfig.spec.initConfiguration.httpsProxy: the https proxy to be used, defaults to none.
MicroK8sConfig.spec.initConfiguration.httpProxy: the http proxy to be used, defaults to none.
MicroK8sConfig.spec.initConfiguration.noProxy: the no-proxy to be used, defaults to none.
MicroK8sConfig.spec.initConfiguration.addons: the list of addons to be enabled, defaults to dns.
MicroK8sConfig.spec.clusterConfiguration.portCompatibilityRemap: option to reuse the security group ports set for kubeadm, defaults to true.
The main purpose of the MicroK8s bootstrap provider is to translate the users needs to a number of cloud-init files applicable for each type of cluster nodes. There are three types of cloud-inits:
The first node cloud-init. That node will be a control plane node and will be the one where the addons are enabled.
The control plane node cloud-init. The control plane nodes need to join a cluster and contribute to its HA.
The worker node cloud-init. These nodes join the cluster as workers.
The cloud-init scripts are saved as secrets that then the infrastructure provider uses during the machine creation. For more information on cloud-init options, see cloud config examples.
In addition, you must always upgrade between Kubernetes minor versions in sequence, e.g. if you need to upgrade from
Kubernetes v1.17 to v1.19, you must first upgrade to v1.18.
For kubeadm based clusters, infrastructure providers require a “machine image” containing pre-installed, matching
versions of kubeadm and kubelet, ensure that relevant infrastructure machine templates reference the appropriate
image for the Kubernetes version.
To upgrade the control plane machines underlying machine images, the MachineTemplate resource referenced by the
KubeadmControlPlane must be changed. Since MachineTemplate resources are immutable, the recommended approach is to
Copy the existing MachineTemplate.
Modify the values that need changing, such as instance type or image ID.
Create the new MachineTemplate on the management cluster.
Modify the existing KubeadmControlPlane resource to reference the new MachineTemplate resource in the infrastructureRef field.
The next step will trigger a rolling update of the control plane using the new values found in the new MachineTemplate.
To upgrade the Kubernetes control plane version make a modification to the KubeadmControlPlane resource’s Spec.Version field. This will trigger a rolling upgrade of the control plane and, depending on the provider, also upgrade the underlying machine image.
Some infrastructure providers, such as AWS, require
that if a specific machine image is specified, it has to match the Kubernetes version specified in the
KubeadmControlPlane spec. In order to only trigger a single upgrade, the new MachineTemplate should be created first
and then both the Version and InfrastructureTemplate should be modified in a single transaction.
The KubeadmControlPlane and MachineDepoyment resources have a field RolloutAfter that can be
set to a timestamp (RFC-3339) after which a rollout should be triggered regardless of whether there
were any changes to KubeadmControlPlane.Spec/MachineDeployment.Spec.Template or not. This would
roll out replacement nodes which can be useful e.g. to perform certificate rotation, reflect changes
to machine templates, move to new machines, etc.
Note that this field can only be used for triggering a rollout, not for delaying one. Specifically,
a rollout can also happen before the time specified in RolloutAfter if any changes are made to
the spec before that time.
The rollout can be triggered by running the following command:
# Trigger a KubeadmControlPlane rollout.
clusterctl alpha rollout restart kubeadmcontrolplane/my-kcp
# Trigger a MachineDeployment rollout.
clusterctl alpha rollout restart machinedeployment/my-md-0
Upgrades are not limited to just the control plane. This section is not related to Kubeadm control plane specifically,
but is the final step in fully upgrading a Cluster API managed cluster.
It is recommended to manage machines with one or more MachineDeployments. MachineDeployments will
transparently manage MachineSets and Machines to allow for a seamless scaling experience. A modification to the
MachineDeployments spec will begin a rolling update of the machines. Follow
these instructions for changing the
template for an existing MachineDeployment.
MachineDeployments support different strategies for rolling out changes to Machines:
RollingUpdate
Changes are rolled out by honouring MaxUnavailable and MaxSurge values.
Only values allowed are of type Int or Strings with an integer and percentage symbol e.g “5%”.
OnDelete
Changes are rolled out driven by the user or any entity deleting the old Machines. Only when a Machine is fully deleted a new one will come up.
Before getting started you should be aware of the expectations that come with using an external etcd cluster.
Cluster API is unable to manage any aspect of the external etcd cluster.
Depending on how you configure your etcd nodes you may incur additional cloud costs in data transfer.
As an example, cross availability zone traffic can cost money on cloud providers. You don’t have to deploy etcd across availability zones, but if you do please be aware of the costs.
To use this, you will need to create an etcd cluster and generate an apiserver-etcd-client certificate and private key. This behaviour can be tested using kubeadm and etcdadm.
CA certificates are required to setup etcd cluster. If you already have a CA then the CA’s crt and key must be copied to /etc/kubernetes/pki/etcd/ca.crt and /etc/kubernetes/pki/etcd/ca.key.
If you do not already have a CA then run command kubeadm init phase certs etcd-ca. This creates two files:
/etc/kubernetes/pki/etcd/ca.crt
/etc/kubernetes/pki/etcd/ca.key
This certificate and private key are used to sign etcd server and peer certificates as well as other client certificates (like the apiserver-etcd-client certificate or the etcd-healthcheck-client certificate). More information on how to setup external etcd with kubeadm can be found here.
Once the etcd cluster is setup, you will need the following files from the etcd cluster:
/etc/kubernetes/pki/apiserver-etcd-client.crt and /etc/kubernetes/pki/apiserver-etcd-client.key
/etc/kubernetes/pki/etcd/ca.crt
You’ll use these files to create the necessary Secrets on the management cluster (see the “Creating the required Secrets” section).
etcdadm creates the CA if one does not exist, uses it to sign its server and peer certificates, and finally to sign the API server etcd client certificate. The CA’s crt and key generated using etcdadm are stored in /etc/etcd/pki/ca.crt and /etc/etcd/pki/ca.key. etcdadm also generates a certificate for the API server etcd client; the certificate and private key are found at /etc/etcd/pki/apiserver-etcd-client.crt and /etc/etcd/pki/apiserver-etcd-client.key, respectively.
Once the etcd cluster has been bootstrapped using etcdadm, you will need the following files from the etcd cluster:
/etc/etcd/pki/apiserver-etcd-client.crt and /etc/etcd/pki/apiserver-etcd-client.key
/etc/etcd/pki/etcd/ca.crt
You’ll use these files in the next section to create the necessary Secrets on the management cluster.
Regardless of the method used to bootstrap the etcd cluster, you will need to use the certificates copied from the etcd cluster to create some Kubernetes Secrets on the management cluster.
In the commands below to create the Secrets, substitute $CLUSTER_NAME with the name of the workload cluster to be created by CAPI, and substitute $CLUSTER_NAMESPACE with the name of the namespace where the workload cluster will be created. The namespace can be omitted if the workload cluster will be created in the default namespace.
First, you will need to create a Secret containing the API server etcd client certificate and key. This command assumes the certificate and private key are in the current directory; adjust your command accordingly if they are not:
# Kubernetes API server etcd client certificate and key
kubectl create secret tls $CLUSTER_NAME-apiserver-etcd-client \
--cert apiserver-etcd-client.crt \
--key apiserver-etcd-client.key \
--namespace $CLUSTER_NAMESPACE
Next, create a Secret for the etcd cluster’s CA certificate. The kubectl create secret tls command requires both a certificate and a key, but the key isn’t needed by CAPI. Instead, use the kubectl create secret generic command, and note that the file containing the CA certificate must be named tls.crt:
# Etcd's CA crt file to validate the generated client certificates
kubectl create secret generic $CLUSTER_NAME-etcd \
--from-file tls.crt \
--namespace $CLUSTER_NAMESPACE
Note: The above commands will base64 encode the certificate/key files by default.
Alternatively you can base64 encode the files and put them in two secrets. The secrets must be formatted as follows and the cert material must be base64 encoded:
Once the Secrets are in place on the management cluster, the rest of the process leverages standard kubeadm configuration. Configure your ClusterConfiguration for the workload cluster as follows:
Create your workload cluster as normal. The new workload cluster should use the configured external etcd nodes instead of creating co-located etcd Pods on the control plane nodes.
Depending on the provider, additional changes to the workload cluster’s manifest may be necessary to ensure the new CAPI-managed nodes have connectivity to the existing etcd nodes. For example, on AWS you will need to leverage the additionalSecurityGroups field on the AWSMachine and/or AWSMachineTemplate objects to add the CAPI-managed nodes to a security group that has connectivity to the existing etcd cluster. Other mechanisms exist for other providers.
Although the clusterctl generate cluster command exposes a number of different configuration values
for customizing workload cluster YAML manifests, some users may need additional flexibility above
and beyond what clusterctl generate cluster or the example “flavor” templates that some CAPI providers
supply (as an example, see these flavor templates
for the Cluster API Provider for Azure). In the future, a templating solution
may be integrated into clusterctl to help address this need, but in the meantime users can use
kustomize as a solution to this need.
This document provides a few examples of using kustomize with Cluster API. All of these examples
assume that you are using a directory structure that looks something like this:
In the overlay directories, the “base” (unmodified) Cluster API configuration (perhaps generated using
clusterctl generate cluster) would be referenced as a resource in kustomization.yaml using ../../base.
Users can use kustomize to specify custom OS images for Cluster API nodes. Using the Cluster API
Provider for AWS (CAPA) as an example, the following kustomization.yaml would leverage a JSON 6902 patch
to modify the AMI for nodes in a workload cluster:
This configuration assumes that the workload cluster only uses MachineDeployments. Since
MachineDeployments and the KubeadmControlPlane both leverage AWSMachineTemplates, this kustomize
configuration would catch all nodes in the workload cluster.
Users could also use kustomize to combine additional resources, like a MachineHealthCheck (MHC), with the
base Cluster API manifest. In an overlay directory, specify the following in kustomization.yaml:
You would want to ensure the clusterName field in the MachineHealthCheck manifest appropriately
matches the name of the workload cluster, taking into account any transformations you may have specified
in kustomization.yaml (like the use of “namePrefix” or “nameSuffix”).
Running kustomize build . with this configuration would append the MHC to the base
Cluster API manifest, thus creating the MHC at the same time as the workload cluster.
The kustomize “namePrefix” and “nameSuffix” transformers are not currently “Cluster API aware.”
Although it is possible to use these transformers with Cluster API manifests, doing so requires separate
patches for Clusters versus infrastructure-specific equivalents (like an AzureCluster or a vSphereCluster).
This can significantly increase the complexity of using kustomize for this use case.
Modifying the transformer configurations for kustomize can make it more effective with Cluster API.
For example, changes to the nameReference transformer in kustomize will enable kustomize to know
about the references between Cluster API objects in a manifest. See
here for more
information on transformer configurations.
Add the following content to the namereference.yaml transformer configuration:
Including this custom configuration in a kustomization.yaml would then enable the use of simple
“namePrefix” and/or “nameSuffix” directives, like this:
Running kustomize build . with this configuration would modify the name of all the Cluster API
objects and the associated referenced objects, adding “blue-” at the beginning and appending “-dev”
at the end.
KCP will generate and manage the admin Kubeconfig for clusters. The client certificate for the admin user is created
with a valid lifespan of a year, and will be automatically regenerated when the cluster is reconciled and has less than
6 months of validity remaining.
We don’t suggest running workloads on control planes, and highly encourage avoiding it unless absolutely necessary.
However, in the case the user wants to run non-control plane workloads on control plane machines they
are ultimately responsible for ensuring the proper functioning of those workloads, given that KCP is not
aware of the specific requirements for each type of workload (e.g. preserving quorum, shutdown procedures etc.).
In order to do so, the user could leverage on the same assumption that applies to all the
Cluster API Machines:
The Kubernetes node hosted on the Machine will be cordoned & drained before removal (with well
known exceptions like full Cluster deletion).
Changes to the following fields of KubeadmControlPlane are propagated in-place to the Machines and do not trigger a full rollout:
.spec.machineTemplate.metadata.labels
.spec.machineTemplate.metadata.annotations
.spec.nodeDrainTimeout
.spec.nodeDeletionTimeout
.spec.nodeVolumeDetachTimeout
Changes to the following fields of KubeadmControlPlane are propagated in-place to the InfrastructureMachine and KubeadmConfig:
.spec.machineTemplate.metadata.labels
.spec.machineTemplate.metadata.annotations
Note: Changes to these fields will not be propagated to Machines, InfraMachines and KubeadmConfigs that are marked for deletion (example: because of scale down).
Cluster API MicroK8s control plane provider (CACPM) is a component responsible for managing the control plane of the provisioned clusters. This implementation uses MicroK8s for cluster provisioning and management.
Currently the CACPM does not expose any functionality. It serves however the following purposes:
Sets the ProviderID on the provisioned nodes. MicroK8s will not set the provider ID automatically so the control plane provider identifies the VMs’ provider IDs and updates the respective machine objects.
Updates the machine state.
Generates and provisions the kubeconfig file used for accessing the cluster. The kubeconfig file is stored as a secret and the user can retrieve via clusterctl.
Several different components of Cluster API leverage infrastructure machine templates,
including KubeadmControlPlane, MachineDeployment, and MachineSet. These
MachineTemplate resources should be immutable, unless the infrastructure provider
documentation indicates otherwise for certain fields (see below for more details).
The correct process for modifying an infrastructure machine template is as follows:
Duplicate an existing template.
Users can use kubectl get <MachineTemplateType> <name> -o yaml > file.yaml
to retrieve a template configuration from a running cluster to serve as a starting
point.
Update the desired fields.
Fields that might need to be modified could include the SSH key, the AWS instance
type, or the Azure VM size. Refer to the provider-specific documentation
for more details on the specific fields that each provider requires or accepts.
Give the newly-modified template a new name by modifying the metadata.name field
(or by using metadata.generateName).
Create the new infrastructure machine template on the API server using kubectl.
(If the template was initially created using the command in step 1, be sure to clear
out any extraneous metadata, including the resourceVersion field, before trying to
send it to the API server.)
Once the new infrastructure machine template has been persisted, users may modify
the object that was referencing the infrastructure machine template. For example,
to modify the infrastructure machine template for the KubeadmControlPlane object,
users would modify the spec.infrastructureTemplate.name field. For a MachineDeployment, users would need to modify the spec.template.spec.infrastructureRef.name
field and the controller would orchestrate the upgrade by managing MachineSets pointing to the new and old references. In the case of a MachineSet with no MachineDeployment owner, if its template reference is changed, it will only affect upcoming Machines.
In all cases, the name field should be updated to point to the newly-modified
infrastructure machine template. This will trigger a rolling update. (This same process
is described in the documentation for upgrading the underlying machine image for
KubeadmControlPlane in the “How to upgrade the underlying
machine image” section.)
Some infrastructure providers may, at their discretion, choose to support in-place
modifications of certain infrastructure machine template fields. This may be useful
if an infrastructure provider is able to make changes to running instances/machines,
such as updating allocated memory or CPU capacity. In such cases, however, Cluster
API will not trigger a rolling update.
Several different components of Cluster API leverage bootstrap templates,
including MachineDeployment, and MachineSet. When used in MachineDeployment or
MachineSet changes to those templates do not trigger rollouts of already existing Machines.
New Machines are created based on the current version of the bootstrap template.
The correct process for modifying a bootstrap template is as follows:
Duplicate an existing template.
Users can use kubectl get <BootstrapTemplateType> <name> -o yaml > file.yaml
to retrieve a template configuration from a running cluster to serve as a starting
point.
Update the desired fields.
Give the newly-modified template a new name by modifying the metadata.name field
(or by using metadata.generateName).
Create the new bootstrap template on the API server using kubectl.
(If the template was initially created using the command in step 1, be sure to clear
out any extraneous metadata, including the resourceVersion field, before trying to
send it to the API server.)
Once the new bootstrap template has been persisted, users may modify
the object that was referencing the bootstrap template. For example,
to modify the bootstrap template for the MachineDeployment object,
users would modify the spec.template.spec.bootstrap.configRef.name field.
The name field should be updated to point to the newly-modified
bootstrap template. This will trigger a rolling update.
Cluster API can be utilized in combination with the Cluster API addon provider for helm (CAAPH) to install and configure a GitOps agent and then the GitOps agent hydrates clusters automatically with various workloads.
Then create and kubectl apply -f the following file on the management cluster to install the ArgoCD agent and the sample guestbook app to the workload cluster via the argo helm charts using CAAPH:
This will automatically install ArgoCD in the ArgoCD namespace and the guestbook application into the guestbook namespace. Adding or labeling additional clusters with argoCDChart: enabled and guestbook: enabled will automatically install the ArgoCD agent and the guestbook application and there is no need to create additional CAAPH HelmChartProxy entries.
The ArgoCD console can be viewed by connecting to the workload cluster and then doing the following:
# Get the admin password
kubectl get secrets argocd-initial-admin-secret -n argocd --template="{{index .data.password | base64decode}}"
kubectl port-forward service/capiargo-argocd-server -n default 8080:443
# and then open the browser on http://localhost:8080 and accept the certificate
The Guestbook application deployment can be seen once logged into the ArgoCD console. Since the GitOps agent points to the git repository, any changes to the repository will automatically update the workload cluster. The git repository could be configured to utilize the App of Apps pattern to install all platform requirements for the cluster. The App of Apps pattern is a single application that installs all other applications and configurations for the cluster.
This same pattern could also utilize the Flux agent using the Flux helm charts being installed and configured by CAAPH.
This section applies only to worker Machines. You can add or remove compute capacity for your cluster workloads by creating or removing Machines. A Machine expresses intent to have a Node with a defined form factor.
Machines can be owned by scalable resources i.e. MachineSet and MachineDeployments.
You can scale MachineSets and MachineDeployments in or out by expressing intent via .spec.replicas or updating the scale subresource e.g kubectl scale machinedeployment foo --replicas=5.
When you delete a Machine directly or by scaling down, the same process takes place in the same order:
The Node backed by that Machine will try to be drained indefinitely and will wait for any volume to be detached from the Node unless you specify a .spec.nodeDrainTimeout.
CAPI uses default kubectl draining implementation with -–ignore-daemonsets=true. If you needed to ensure DaemonSets eviction you’d need to do so manually by also adding proper taints to avoid rescheduling.
The infrastructure backing that Node will try to be deleted indefinitely.
Only when the infrastructure is gone, the Node will try to be deleted indefinitely unless you specify .spec.nodeDeletionTimeout.
This section applies only to worker Machines. Cluster Autoscaler is a tool that automatically adjusts the size of the Kubernetes cluster based
on the utilization of Pods and Nodes in your cluster. For more general information about the
Cluster Autoscaler, please see the
project documentation.
The following instructions are a reproduction of the Cluster API provider specific documentation
from the Autoscaler project documentation.
The cluster autoscaler on Cluster API uses
the cluster-api project to
manage the provisioning and de-provisioning of nodes within a Kubernetes
cluster.
To enable the Cluster API provider, you must first specify it in the command
line arguments to the cluster autoscaler binary. For example:
cluster-autoscaler --cloud-provider=clusterapi
Please note, this example only shows the cloud provider options, you will
most likely need other command line flags. For more information you can invoke
cluster-autoscaler --help to see a full list of options.
These can be mixed and matched in any combination, for example to only match resources
in the staging namespace, belonging to the purple cluster, with the label owner=jim:
You will also need to provide the path to the kubeconfig(s) for the management
and workload cluster you wish cluster-autoscaler to run against. To specify the
kubeconfig path for the workload cluster to monitor, use the --kubeconfig
option and supply the path to the kubeconfig. If the --kubeconfig option is
not specified, cluster-autoscaler will attempt to use an in-cluster configuration.
To specify the kubeconfig path for the management cluster to monitor, use the
--cloud-config option and supply the path to the kubeconfig. If the
--cloud-config option is not specified it will fall back to using the kubeconfig
that was provided with the --kubeconfig option.
To enable the automatic scaling of components in your cluster-api managed
cloud there are a few annotations you need to provide. These annotations
must be applied to either MachineSet, MachineDeployment, or MachinePool
resources depending on the type of cluster-api mechanism that you are using.
There are two annotations that control how a cluster resource should be scaled:
cluster.x-k8s.io/cluster-api-autoscaler-node-group-min-size - This specifies
the minimum number of nodes for the associated resource group. The autoscaler
will not scale the group below this number. Please note that the cluster-api
provider will not scale down to, or from, zero unless that capability is enabled
(see Scale from zero support).
cluster.x-k8s.io/cluster-api-autoscaler-node-group-max-size - This specifies
the maximum number of nodes for the associated resource group. The autoscaler
will not scale the group above this number.
The autoscaler will monitor any MachineSet, MachineDeployment, or MachinePool containing
both of these annotations.
Note: MachinePool support in cluster-autoscaler requires a provider implementation
that supports the new “MachinePool Machines” feature. MachinePools in Cluster API are
considered an experimental feature and are not enabled by default.
The Cluster API community has defined an opt-in method for infrastructure
providers to enable scaling from zero-sized node groups in the
Opt-in Autoscaling from Zero enhancement.
As defined in the enhancement, each provider may add support for scaling from
zero to their provider, but they are not required to do so. If you are expecting
built-in support for scaling from zero, please check with the Cluster API
infrastructure providers that you are using.
If your Cluster API provider does not have support for scaling from zero, you
may still use this feature through the capacity annotations. You may add these
annotations to your MachineDeployments, or MachineSets if you are not using
MachineDeployments (it is not needed on both), to instruct the cluster
autoscaler about the sizing of the nodes in the node group. At the minimum,
you must specify the CPU and memory annotations, these annotations should
match the expected capacity of the nodes created from the infrastructure.
For example, if my MachineDeployment will create nodes that have “16000m” CPU,
“128G” memory, “100Gi” ephemeral disk storage, 2 NVidia GPUs, and can support
200 max pods, the following annotations will instruct the autoscaler how to
expand the node group from zero replicas:
apiVersion: cluster.x-k8s.io/v1alpha4
kind: MachineDeployment
metadata:
annotations:
cluster.x-k8s.io/cluster-api-autoscaler-node-group-max-size: "5"
cluster.x-k8s.io/cluster-api-autoscaler-node-group-min-size: "0"
capacity.cluster-autoscaler.kubernetes.io/memory: "128G"
capacity.cluster-autoscaler.kubernetes.io/cpu: "16"
capacity.cluster-autoscaler.kubernetes.io/ephemeral-disk: "100Gi"
capacity.cluster-autoscaler.kubernetes.io/maxPods: "200"
// Device Plugin
// Comment out the below annotation if DRA is enabled on your cluster running k8s v1.32.0 or greater
capacity.cluster-autoscaler.kubernetes.io/gpu-type: "nvidia.com/gpu"
// Dynamic Resource Allocation (DRA)
// Uncomment the below annotation if DRA is enabled on your cluster running k8s v1.32.0 or greater
// capacity.cluster-autoscaler.kubernetes.io/dra-driver: "gpu.nvidia.com"
// Common in Device Plugin and DRA
capacity.cluster-autoscaler.kubernetes.io/gpu-count: "2"
Note the maxPods annotation will default to 110 if it is not supplied.
This value is inspired by the Kubernetes best practices
Considerations for large clusters.
Note User should select the annotation for GPU either gpu-type or dra-driver depends on whether using Device Plugin or Dynamic Resource Allocation(DRA). gpu-count is a common parameter in both.
If you are using the opt-in support for scaling from zero as defined by the
Cluster API infrastructure provider, you will need to add the infrastructure
machine template types to your role permissions for the service account
associated with the cluster autoscaler deployment. The service account will
need permission to get, list, and watch the infrastructure machine
templates for your infrastructure provider.
For example, when using the Kubemark provider
you will need to set the following permissions:
rules:
- apiGroups:
- infrastructure.cluster.x-k8s.io
resources:
- kubemarkmachinetemplates
verbs:
- get
- list
- watch
To provide labels or taint information for scale from zero, the optional
capacity annotations may be supplied as a comma separated list, as
demonstrated in the example below:
Custom autoscaling options per node group (MachineDeployment/MachinePool/MachineSet) can be specified as annoations with a common prefix:
apiVersion: cluster.x-k8s.io/v1beta1
kind: MachineDeployment
metadata:
annotations:
# overrides --scale-down-utilization-threshold global value for that specific MachineDeployment
cluster.x-k8s.io/autoscaling-options-scaledownutilizationthreshold: "0.5"
# overrides --scale-down-gpu-utilization-threshold global value for that specific MachineDeployment
cluster.x-k8s.io/autoscaling-options-scaledowngpuutilizationthreshold: "0.5"
# overrides --scale-down-unneeded-time global value for that specific MachineDeployment
cluster.x-k8s.io/autoscaling-options-scaledownunneededtime: "10m0s"
# overrides --scale-down-unready-time global value for that specific MachineDeployment
cluster.x-k8s.io/autoscaling-options-scaledownunreadytime: "20m0s"
# overrides --max-node-provision-time global value for that specific MachineDeployment
cluster.x-k8s.io/autoscaling-options-maxnodeprovisiontime: "20m0s"
Users of single-arch non-amd64 clusters who are using scale from zero
support should also set the CAPI_SCALE_ZERO_DEFAULT_ARCH environment variable
to set the architecture of the nodes they want to default the node group templates to.
The autoscaler will default to amd64 if it is not set, and the node
group templates may not match the nodes’ architecture, specifically when
the workload triggering the scale-up uses a node affinity predicate checking
for the node’s architecture.
By default all Kubernetes resources consumed by the Cluster API provider will
use the group cluster.x-k8s.io, with a dynamically acquired version. In
some situations, such as testing or prototyping, you may wish to change this
group variable. For these situations you may use the environment variable
CAPI_GROUP to change the group that the provider will use.
Please note that setting the CAPI_GROUP environment variable will also cause the
annotations for minimum and maximum size to change.
This behavior will also affect the machine annotation on nodes, the machine deletion annotation,
and the cluster name label. For example, if CAPI_GROUP=test.k8s.io
then the minimum size annotation key will be test.k8s.io/cluster-api-autoscaler-node-group-min-size,
the machine annotation on nodes will be test.k8s.io/machine, the machine deletion
annotation will be test.k8s.io/delete-machine, and the cluster name label will be
test.k8s.io/cluster-name.
When determining the group version for the Cluster API types, by default the autoscaler
will look for the latest version of the group. For example, if MachineDeployments
exist in the cluster.x-k8s.io group at versions v1alpha1 and v1beta1, the
autoscaler will choose v1beta1.
In some cases it may be desirable to specify which version of the API the cluster
autoscaler should use. This can be useful in debugging scenarios, or in situations
where you have deployed multiple API versions and wish to ensure that the autoscaler
uses a specific version.
Setting the CAPI_VERSION environment variable will instruct the autoscaler to use
the version specified. This works in a similar fashion as the API group environment
variable with the exception that there is no default value. When this variable is not
set, the autoscaler will use the behavior described above.
A sample manifest
that will create a deployment running the autoscaler is
available. It can be deployed by passing it through envsubst, providing
these environment variables to set the namespace to deploy into as well as the image and tag to use:
The cluster-autoscaler-management role for accessing cluster api scalable resources is scoped to ClusterRole.
This may not be ideal for all environments (eg. Multi tenant environments).
In such cases, it is recommended to scope it to a Role mapped to a specific namespace.
For users using ClusterClass and Managed Topologies the Cluster Topology controller attempts to set MachineDeployment replicas based on the spec.topology.workers.machineDeployments[].replicas field. In order to use the Cluster Autoscaler this field can be left unset in the Cluster definition.
The below Cluster definition shows which field to leave unset:
Warning: If the Autoscaler is enabled and the replicas field is set for a MachineDeployment or MachineSet the Cluster may enter a broken state where replicas become unpredictable.
If the replica field is unset in the Cluster definition Autoscaling can be enabled as described above
As with other providers, if the device plugin on nodes that provides GPU
resources takes some time to advertise the GPU resource to the cluster, this
may cause Cluster Autoscaler to unnecessarily scale out multiple times.
To avoid this, you can configure kubelet on your GPU nodes to label the node
before it joins the cluster by passing it the --node-labels flag. For the
CAPI cloudprovider, the label format is as follows:
cluster-api/accelerator=<gpu-type>
<gpu-type> is arbitrary.
It is important to note that if you are using the --gpu-total flag to limit the number
of GPU resources in your cluster that the <gpu-type> value must match
between the command line flag and the node labels. Setting these values incorrectly
can lead to the autoscaler creating too many GPU resources.
For example, if you are using the autoscaler command line flag
--gpu-total=gfx-hardware:1:2 to limit the number of gfx-hardware resources
to a minimum of 1 and maximum of 2, then you should use the kubelet node label flag
--node-labels=cluster-api/accelerator=gfx-hardware.
The Cluster Autoscaler feature to enable balancing similar node groups
(activated with the --balance-similar-node-groups flag) is a powerful and
popular feature. When enabled, the Cluster Autoscaler will attempt to create
new nodes by adding them in a manner that balances the creation between
similar node groups. With Cluster API, these node groups correspond directly
to the scalable resources associated (usually MachineDeployments and MachineSets)
with the nodes in question. In order for the nodes of these scalable resources
to be considered similar by the Cluster Autoscaler, they must have the same
capacity, labels, and taints for the nodes which will be created from them.
To help assist the Cluster Autoscaler in determining which node groups are
similar, the command line flags --balancing-ignore-label and
--balancing-label are provided. For an expanded discussion about balancing
similar node groups and the options which are available, please see the
Cluster Autoscaler FAQ.
Because Cluster API can address many different cloud providers, it is important
to configure the balancing labels to ignore provider-specific labels which
are used for carrying zonal information on Kubernetes nodes. The Cluster
Autoscaler implementation for Cluster API does not assume any labels (aside from
the well-known Kubernetes labels)
to be ignored when running. Users must configure their Cluster Autoscaler deployment
to ignore labels which might be different between nodes, but which do not
otherwise affect node behavior or size (for example when two MachineDeployments
are the same except for their deployment zones). The Cluster API community has
decided not to carry cloud provider specific labels in the Cluster Autoscaler
to reduce the possibility for labels to clash between providers. Additionally,
the community has agreed to promote documentation and the use of the --balancing-ignore-label
flag as the preferred method of deployment to reduce the extended need for
maintenance on the Cluster Autoscaler when new providers are added or updated.
For further context around this decision, please see the
Cluster API Deep Dive into Cluster Autoscaler Node Group Balancing discussion from 2022-09-12.
The following table shows some of the most common labels used by cloud providers
to designate regional or zonal information on Kubernetes nodes. It is shared
here as a reference for users who might be deploying on these infrastructures.
Cloud Provider
Label to ignore
Notes
Alibaba Cloud
topology.diskplugin.csi.alibabacloud.com/zone
Used by the Alibaba Cloud CSI driver as a target for persistent volume node affinity
AWS
alpha.eksctl.io/instance-id
Used by eksctl to identify instances
AWS
alpha.eksctl.io/nodegroup-name
Used by eksctl to identify node group names
AWS
eks.amazonaws.com/nodegroup
Used by EKS to identify node groups
AWS
k8s.amazonaws.com/eniConfig
Used by the AWS CNI for custom networking
AWS
lifecycle
Used by AWS as a label for spot instances
AWS
topology.ebs.csi.aws.com/zone
Used by the AWS EBS CSI driver as a target for persistent volume node affinity
Azure
topology.disk.csi.azure.com/zone
Used as the topology key by the Azure Disk CSI driver
Azure
agentpool
Legacy label used to specify to which Azure node pool a particular node belongs
Azure
kubernetes.azure.com/agentpool
Used by AKS to identify to which node pool a particular node belongs
GCE
topology.gke.io/zone
Used to specify the zone of the node
IBM Cloud
ibm-cloud.kubernetes.io/worker-id
Used by the IBM Cloud Cloud Controller Manager to identify the node
IBM Cloud
vpc-block-csi-driver-labels
Used by the IBM Cloud CSI driver as a target for persistent volume node affinity
Before attempting to configure a MachineHealthCheck, you should have a working management cluster with at least one MachineDeployment or MachineSet deployed.
A MachineHealthCheck is a resource within the Cluster API which allows users to define conditions under which Machines within a Cluster should be considered unhealthy.
A MachineHealthCheck is defined on a management cluster and scoped to a particular workload cluster.
When defining a MachineHealthCheck, users specify a timeout for each of the conditions that they define to check on the Machine’s Node.
If any of these conditions are met for the duration of the timeout, the Machine will be remediated.
By default, the action of remediating a Machine should trigger a new Machine to be created to replace the failed one, but providers are allowed to plug in more sophisticated external remediation solutions.
Use the following example as a basis for creating a MachineHealthCheck for worker nodes:
apiVersion: cluster.x-k8s.io/v1beta1
kind: MachineHealthCheck
metadata:
name: capi-quickstart-node-unhealthy-5m
spec:
# clusterName is required to associate this MachineHealthCheck with a particular cluster
clusterName: capi-quickstart
# (Optional) maxUnhealthy prevents further remediation if the cluster is already partially unhealthy
maxUnhealthy: 40%
# (Optional) nodeStartupTimeout determines how long a MachineHealthCheck should wait for
# a Node to join the cluster, before considering a Machine unhealthy.
# Defaults to 10 minutes if not specified.
# Set to 0 to disable the node startup timeout.
# Disabling this timeout will prevent a Machine from being considered unhealthy when
# the Node it created has not yet registered with the cluster. This can be useful when
# Nodes take a long time to start up or when you only want condition based checks for
# Machine health.
nodeStartupTimeout: 10m
# selector is used to determine which Machines should be health checked
selector:
matchLabels:
nodepool: nodepool-0
# Conditions to check on Nodes for matched Machines, if any condition is matched for the duration of its timeout, the Machine is considered unhealthy
unhealthyConditions:
- type: Ready
status: Unknown
timeout: 300s
- type: Ready
status: "False"
timeout: 300s
Use this example as the basis for defining a MachineHealthCheck for control plane nodes managed via
the KubeadmControlPlane:
KubeadmControlPlane allows to control how remediation happen by defining an optional remediationStrategy;
this feature can be used for preventing unnecessary load on infrastructure provider e.g. in case of quota problems,or for allowing the infrastructure provider to stabilize in case of temporary problems.
maxRetry is the maximum number of retries while attempting to remediate an unhealthy machine.
A retry happens when a machine that was created as a replacement for an unhealthy machine also fails.
For example, given a control plane with three machines M1, M2, M3:
M1 become unhealthy; remediation happens, and M1-1 is created as a replacement.
If M1-1 (replacement of M1) has problems while bootstrapping it will become unhealthy, and then be
remediated. This operation is considered a retry - remediation-retry #1.
If M1-2 (replacement of M1-1) becomes unhealthy, remediation-retry #2 will happen, etc.
A retry will only happen after the retryPeriod from the previous retry has elapsed. If retryPeriod is not set (default), a retry will happen immediately.
If a machine is marked as unhealthy after minHealthyPeriod (default 1h) has passed since the previous remediation this is no longer considered a retry because the new issue is assumed unrelated from the previous one.
If maxRetry is not set (default), remediation will be retried infinitely.
To ensure that MachineHealthChecks only remediate Machines when the cluster is healthy,
short-circuiting is implemented to prevent further remediation via the maxUnhealthy and unhealthyRange fields within the MachineHealthCheck spec.
If the user defines a value for the maxUnhealthy field (either an absolute number or a percentage of the total Machines checked by this MachineHealthCheck),
before remediating any Machines, the MachineHealthCheck will compare the value of maxUnhealthy with the number of Machines it has determined to be unhealthy.
If the number of unhealthy Machines exceeds the limit set by maxUnhealthy, remediation will not be performed.
If the user defines a value for the unhealthyRange field (bracketed values that specify a start and an end value), before remediating any Machines,
the MachineHealthCheck will check if the number of Machines it has determined to be unhealthy is within the range specified by unhealthyRange.
If it is not within the range set by unhealthyRange, remediation will not be performed.
If unhealthyRange is set to [3-5] and there are 10 Machines being checked:
If 2 or fewer nodes are unhealthy, remediation will not be performed.
If 6 or more nodes are unhealthy, remediation will not be performed.
In all other cases, remediation will be performed.
Note, the above example had 10 machines as sample set. But, this would work the same way for any other number.
This is useful for dynamically scaling clusters where the number of machines keep changing frequently.
There are scenarios where remediation for a machine may be undesirable (eg. during cluster migration using clusterctl move). For such cases, MachineHealthCheck skips marking a Machine for remediation if:
the Machine has the cluster.x-k8s.io/skip-remediation annotation
the Machine has the cluster.x-k8s.io/paused annotation
the MachineHealthCheck has the cluster.x-k8s.io/paused annotation
Before deploying a MachineHealthCheck, please familiarise yourself with the following limitations and caveats:
Only Machines owned by a MachineSet or a KubeadmControlPlane can be remediated by a MachineHealthCheck (since a MachineDeployment uses a MachineSet, then this includes Machines that are part of a MachineDeployment)
The following rules should be satisfied in order to start remediation of a control plane machine:
One of the following apply:
The cluster MUST not be initialized yet (the failure happens before KCP reaches the initialized state)
The cluster MUST have at least two control plane machines, because this is the smallest cluster size that can be remediated.
Previous remediation (delete and re-create) MUST have been completed. This rule prevents KCP from remediating more machines while the replacement for the previous machine is not yet created.
The cluster MUST have no machines with a deletion timestamp. This rule prevents KCP taking actions while the cluster is in a transitional state.
Remediation MUST preserve etcd quorum. This rule ensures that we will not remove a member that would result in etcd losing a majority of members and thus become unable to field new requests (note: this rule applies only to CP already initialized and with managed etcd)
If the Node for a Machine is removed from the cluster, a MachineHealthCheck will consider this Machine unhealthy and remediate it immediately
If no Node joins the cluster for a Machine after the NodeStartupTimeout, the Machine will be remediated
Important: if the kubelet on the node hosting the etcd leader member is not working, this prevents KCP from doing some checks it is expecting to do on the leader - and specifically on the leader -.
This prevents remediation to happen. There are ongoing discussions about how to overcome this limitation in https://github.com/kubernetes-sigs/cluster-api/issues/8465; as of today users facing this situation
are recommended to manually forward leadership to another etcd member and manually delete the corresponding machine.
Machine deletions occur in various cases, for example:
Control plane (e.g. KCP) or MachineDeployment rollouts
Scale downs of MachineDeployments / MachineSets
Machine remediations
Machine deletions (e.g. kubectl delete machine)
This page describes how Cluster API deletes Machines.
Machine deletion can be broken down into the following phases:
Machine deletion is triggered (i.e. the metadata.deletionTimestamp is set)
Machine controller waits until all pre-drain hooks succeeded, if any are registered
Pre-drain hooks can be registered by adding annotations with the pre-drain.delete.hook.machine.cluster.x-k8s.io prefix to the Machine object
Machine controller checks if the Machine should be drained, drain is skipped if:
The Machine has the machine.cluster.x-k8s.io/exclude-node-draining annotation
The Machine.spec.nodeDrainTimeout field is set and already expired (unset or 0 means no timeout)
The Machine is owned by a KubeadmControlPlane and the pre-terminate hook has been already removed
If the Machine should be drained, the Machine controller evicts all relevant Pods from the Node (see details in Node drain)
Machine controller checks if we should wait until all volumes are detached, this is skipped if:
The Machine has the machine.cluster.x-k8s.io/exclude-wait-for-node-volume-detach annotation
The Machine.spec.nodeVolumeDetachTimeout field is set and already expired (unset or 0 means no timeout)
The Machine is owned by a KubeadmControlPlane and the pre-terminate hook has been already removed
If we should wait for volume detach, the Machine controller waits until Node.status.volumesAttached is empty
and there are no more VolumeAttachment objects that indicate that there are still volumes attached to the Node
Typically the volumes are getting detached by CSI after the corresponding Pods have been evicted during drain
Machine controller waits until all pre-terminate hooks succeeded, if any are registered
Pre-terminate hooks can be registered by adding annotations with the pre-terminate.delete.hook.machine.cluster.x-k8s.io prefix to the Machine object
Machine controller deletes the InfrastructureMachine object (e.g. DockerMachine) of the Machine and waits until it is gone
Machine controller deletes the BootstrapConfig object (e.g. KubeadmConfig) of the machine and waits until it is gone
Machine controller deletes the Node object in the workload cluster
Node deletion will be retried until either the Node object is gone or Machine.spec.nodeDeletionTimeout is expired (0 means no timeout, but the field defaults to 10s)
Note: Nodes are usually also deleted by cloud controller managers, which is why Cluster API per default only tries to delete Nodes for 10s.
Note: There are cases where Node drain, wait for volume detach and Node deletion is skipped. For these please take a look at the
implementation of the isDeleteNodeAllowed function.
This section describes details of the Node drain process in Cluster API. Cluster API implements Node drain aligned
with kubectl drain. One major difference is that the Cluster API controller does not actively wait during Reconcile
until all Pods are drained from the Node. Instead it continuously evicts Pods and requeues after 20s until all relevant
Pods have been drained from the Node or until the Machine.spec.nodeDrainTimeout is reached (if configured).
Node drain can be broken down into the following phases:
Node is cordoned (i.e. the Node.spec.unschedulable field is set, which leads to the node.kubernetes.io/unschedulable:NoSchedule taint being added to the Node)
This prevents that Pods that already have been evicted are rescheduled to the same Node. Please only tolerate this taint
if you know what you are doing! Otherwise it can happen that the Machine controller is stuck continuously evicting the same Pods.
Machine controller calculates the list of Pods that have to be drained from the Node. Pods can be categorized as follows:
Pods that are skipped/ignored during drain:
Pods belonging to an existing DaemonSet (orphaned DaemonSet Pods have to be evicted as well)
Mirror Pods, i.e. Pods with the kubernetes.io/config.mirror annotation (usually static Pods managed by kubelet, like kube-apiserver)
Pods with the cluster.x-k8s.io/drain=skip label
Pods that match a MachineDrainRule with behavior Skip
Pods that should not be evicted, but we have to wait for their completion:
Pods with the cluster.x-k8s.io/drain=wait-completed label
Pods that match a MachineDrainRule with behavior WaitCompleted
Pods that should be evicted:
Pods that match a MachineDrainRule with behavior Drain
All Pods not belonging to any of the other categories
If there are no more Pods that have to be drained Node drain is completed
Otherwise we have to wait for Pods to complete and/or evict Pods
There are various reasons why an eviction could fail:
The eviction would violate a PodDisruptionBudget, i.e. not enough Pod replicas would be available if the Pod would be evicted
The namespace is in terminating, in this case the kube-controller-manager is responsible for setting the .metadata.deletionTimestamp on the Pod
Other errors, e.g. a connection issue when calling the eviction API of the workload cluster
Please note that when an eviction goes through, this only means that the .metadata.deletionTimestamp is set on the Pod, but the
Pod also has to be terminated and the Pod object has to go away for the drain to complete.
These steps are repeated every 20s until all relevant Pods have been drained from the Node
Per default all Pods are drained at the same time. But with MachineDrainRules it’s also possible to define a drain order
for Pods with behavior Drain (Pods with WaitCompleted have a hard-coded order of 0). The Machine controller will drain
Pods in batches based on their order (from highest to lowest order).
For more details about MachineDrainRules, please see the corresponding proposal.
Special cases:
If the Node doesn’t exist anymore, Node drain is entirely skipped
If the Node is unreachable (i.e. the Node Ready condition is in status Unknown):
Pods with .metadata.deletionTimestamp more than 1s in the past are ignored
Pod evictions will use 1s GracePeriodSeconds, i.e. the terminationGracePeriodSeconds field from the Pod spec will be ignored.
Note: PodDisruptionBudgets are still respected, because both of these changes are only relevant if the call to trigger the Pod eviction goes through.
But Pod eviction calls are rejected when PodDisruptionBudgets would be violated by the eviction.
The drain process can be observed through the DrainingSucceeded condition on the Machine and various logs.
Example condition
To determine which Pods are blocking the drain and why you can take a look at the DrainingSucceeded condition on the Machine, e.g.:
status:
...
conditions:
...
- lastTransitionTime: "2024-08-30T13:36:27Z"
message: |-
Drain not completed yet:
* Pods with deletionTimestamp that still exist: cert-manager/cert-manager-756d54fb98-hcb6k
* Pods with eviction failed:
* Cannot evict pod as it would violate the pod's disruption budget. The disruption budget nginx needs 10 healthy pods and has 10 currently: test-namespace/nginx-deployment-6886c85ff7-2jtqm, test-namespace/nginx-deployment-6886c85ff7-7ggsd, test-namespace/nginx-deployment-6886c85ff7-f6z4s, ... (7 more)
reason: Draining
severity: Info
status: "False"
type: DrainingSucceeded
I0830 12:52:58.739093 17 drain.go:172] "Drain not completed yet, there are still Pods on the Node that have to be drained" ... Node="my-cluster-md-0-wxtcg-mtg57-ssfg8" podsToTriggerEviction="test-namespace/nginx-deployment-6886c85ff7-4r297, test-namespace/nginx-deployment-6886c85ff7-5gl2h, test-namespace/nginx-deployment-6886c85ff7-64tf9, test-namespace/nginx-deployment-6886c85ff7-9k5gp, test-namespace/nginx-deployment-6886c85ff7-9mdjw, ... (5 more)" podsWithDeletionTimestamp="kube-system/calico-kube-controllers-7dc5458bc6-rdjj4, kube-system/coredns-7db6d8ff4d-9cbhn"
On log level 4 it is possible to observe details of the Pod evictions, e.g.:
After Pods have been evicted, either the drain is directly completed:
I0830 13:29:56.235398 17 machine_controller.go:727] "Drain completed, remaining Pods on the Node have been evicted" ... Node="my-cluster-2-md-0-wxtcg-mtg57-24lvh"
If this doesn’t happen, please take a closer at the logs to determine which Pods still have to be evicted or haven’t gone away yet
(i.e. deletionTimestamp is set but the Pod objects still exist).
Cluster API now ships with a new experimental package that lives under the exp/ directory. This is a
temporary location for features which will be moved to their permanent locations after graduation. Users can experiment with these features by enabling them using feature gates.
Currently Cluster API has the following experimental features:
PriorityQueue (env var: EXP_PRIORITY_QUEUE): Enables the usage of the controller-runtime PriorityQueue: https://github.com/kubernetes-sigs/controller-runtime/issues/2374
During Machine drain the Machine controller waits for volumes to be detached. Per default, the controller considers
Nodes.status.volumesAttached and VolumesAttachments. This feature flag allows to opt-out from considering VolumeAttachments.
The feature gate was added to allow to opt-out in case unforeseen issues occur with VolumeAttachments.
As an alternative to environment variables, it is also possible to set variables in the clusterctl config file located at $XDG_CONFIG_HOME/cluster-api/clusterctl.yaml, e.g.:
# Values for environment variable substitution
EXP_SOME_FEATURE_NAME: "true"
In case a variable is defined in both the config file and as an OS environment variable, the environment variable takes precedence.
For more information on how to set variables for clusterctl, see clusterctl Configuration File
Some features like MachinePools may require infrastructure providers to implement a separate CRD that handles the infrastructure side of the feature too.
For such a feature to work, infrastructure providers should also enable their controllers if it is implemented as a feature. If it is not implemented as a feature, no additional step is necessary.
As an example, Cluster API Provider Azure (CAPZ) has support for MachinePool through the infrastructure type AzureMachinePool.
To enable/disable features on existing management clusters, users can edit the corresponding controller manager
deployments, which will then trigger a restart with the requested features. E.g. for the CAPI controller manager
deployment:
Warning: Experimental features are unreliable, i.e., some may one day be promoted to the main repository, or they may be modified arbitrarily or even disappear altogether.
In short, they are not subject to any compatibility or deprecation promise.
The MachinePool feature provides a way to manage a set of machines by defining a common configuration, number of desired machine replicas etc. similar to MachineDeployment,
except MachineSet controllers are responsible for the lifecycle management of the machines for MachineDeployment, whereas in MachinePools,
each infrastructure provider has a specific solution for orchestrating these Machines.
Feature gate name: MachinePool
Variable name to enable/disable the feature gate: EXP_MACHINE_POOL
Infrastructure providers can support this feature by implementing their specific MachinePool such as AzureMachinePool.
Although MachinePools provide a similar feature to MachineDeployments, MachinePools do so by leveraging an InfraMachinePool which corresponds 1:1 with a resource like VMSS on Azure or Autoscaling Groups on AWS which we treat as a black box. When a MachinePool is scaled up, the InfraMachinePool scales itself up and populates its provider ID list based on the response from the infrastructure provider. On the other hand, when a MachineDeployment is scaled up, new Machines are created which then create an individual InfraMachine, which corresponds to a VM in any infrastructure provider.
MachinePools
MachineDeployments
Creates new instances through a single infrastructure resource like VMSS in Azure or Autoscaling Groups in AWS.
Creates new instances by creating new Machines, which create individual VM instances on the infra provider.
Set of instances is orchestrated by the infrastructure provider.
Set of instances is orchestrated by Cluster API using a MachineSet.
Each MachinePool corresponds 1:1 with an associated InfraMachinePool.
Each MachineDeployment includes a MachineSet, and for each replica, it creates a Machine and InfraMachine.
Each MachinePool requires only a single BootstrapConfig.
Each MachineDeployment uses an InfraMachineTemplate and a BootstrapConfigTemplate, and each Machine requires a unique BootstrapConfig.
Maintains a list of instances in the providerIDList field in the MachinePool spec. This list is populated based on the response from the infrastructure provider.
Maintains a list of instances through the Machine resources owned by the MachineSet.
The MachineSetPreflightChecks feature can provide additional safety while creating new Machines and remediating existing unhealthy Machines of a MachineSet.
When a MachineSet creates machines under certain circumstances, the operation fails or leads to a new machine that will be deleted and recreated in a short timeframe,
leading to unwanted Machine churn. Some of these circumstances include, but not limited to, creating a new Machine when Kubernetes version skew could be violated or
joining a Machine when the Control Plane is upgrading leading to failure because of mixed kube-apiserver version or due to the cluster load balancer delays in adapting
to the changes.
Enabling MachineSetPreflightChecks provides safety in such circumstances by making sure that a Machine is only created when it is safe to do so.
Feature gate name: MachineSetPreflightChecks
Variable name to enable/disable the feature gate: EXP_MACHINE_SET_PREFLIGHT_CHECKS
This preflight check ensures that the MachineSet and the ControlPlane have the same version. The idea behind this
check is that it doesn’t make sense to create a Machine with an old version, if we already know based on the control
plane version that the Machine has to be replaced soon.
This preflight check is only performed if:
The Cluster has a managed topology
The Cluster uses a ControlPlane provider.
ControlPlane version is defined (ControlPlane.spec.version is set).
MachineSet version is defined (MachineSet.spec.template.spec.version is set).
Per default all preflight checks are enabled for all MachineSets including new and existing MachineSets.
The enabled preflight checks can be overwritten with the --machineset-preflight-checks command-line flag.
It is also possible to opt-out of one or all of the preflight checks on a per MachineSet basis by specifying a
comma-separated list of the preflight checks via the machineset.cluster.x-k8s.io/skip-preflight-checks annotation
on the MachineSet.
Examples:
To opt out of all the preflight checks set the machineset.cluster.x-k8s.io/skip-preflight-checks: All annotation.
To opt out of the ControlPlaneIsStable preflight check set the machineset.cluster.x-k8s.io/skip-preflight-checks: ControlPlaneIsStable annotation.
To opt out of multiple preflight checks set the machineset.cluster.x-k8s.io/skip-preflight-checks: ControlPlaneIsStable,KubernetesVersionSkew annotation.
The ClusterClass feature introduces a new way to create clusters which reduces boilerplate and enables flexible and powerful customization of clusters.
ClusterClass is a powerful abstraction implemented on top of existing interfaces and offers a set of tools and operations to streamline cluster lifecycle management while maintaining the same underlying API.
Feature gate name: ClusterTopology
Variable name to enable/disable the feature gate: CLUSTER_TOPOLOGY
Creating a Cluster: Quick Start guide
Please note that the experience for creating a Cluster using ClusterClass is very similar to the one for creating a standalone Cluster. Infrastructure providers supporting ClusterClass provide Cluster templates leveraging this feature (e.g the Docker infrastructure provider has a development-topology template).
A ClusterClass becomes more useful and valuable when it can be used to create many Cluster of a similar
shape. The goal of this document is to explain how ClusterClasses can be written in a way that they are
flexible enough to be used in as many Clusters as possible by supporting variants of the same base Cluster shape.
The following example shows a basic ClusterClass. It contains templates to shape the control plane,
infrastructure and workers of a Cluster. When a Cluster is using this ClusterClass, the templates
are used to generate the objects of the managed topology of the Cluster.
The following example shows a Cluster using this ClusterClass. In this case a KubeadmControlPlane
with the corresponding DockerMachineTemplate, a DockerCluster and a MachineDeployment with
the corresponding KubeadmConfigTemplate and DockerMachineTemplate will be created. This basic
ClusterClass is already very flexible. Via the topology on the Cluster the following can be configured:
.spec.topology.version: the Kubernetes version of the Cluster
.spec.topology.controlPlane: ControlPlane replicas and their metadata
.spec.topology.workers: MachineDeployments and their replicas, metadata and failure domain
The ClusterClass name should be generic enough to make sense across multiple clusters, i.e. a
name which corresponds to a single Cluster, e.g. “my-cluster”, is not recommended.
Try to keep the ClusterClass names short and consistent (if you publish multiple ClusterClasses).
As a ClusterClass usually evolves over time and you might want to rebase Clusters from one version
of a ClusterClass to another, consider including a version suffix in the ClusterClass name.
For more information about changing a ClusterClass please see: Changing a ClusterClass.
Prefix the templates used in a ClusterClass with the name of the ClusterClass.
Don’t reuse the same template in multiple ClusterClasses. This is automatically taken care
of by prefixing the templates with the name of the ClusterClass.
ClusterClass also supports MachinePool workers. They work very similar to MachineDeployments. MachinePools
can be specified in the ClusterClass template under the workers section like so:
MachineHealthChecks can be configured in the ClusterClass for the control plane and for a
MachineDeployment class. The following configuration makes sure a MachineHealthCheck is
created for the control plane and for every MachineDeployment using the default-worker class.
As shown above, basic ClusterClasses are already very powerful. But there are cases where
more powerful mechanisms are required. Let’s assume you want to manage multiple Clusters
with the same ClusterClass, but they require different values for a field in one of the
referenced templates of a ClusterClass.
A concrete example would be to deploy Clusters with different registries. In this case,
every cluster needs a Cluster-specific value for .spec.kubeadmConfigSpec.clusterConfiguration.imageRepository
in KubeadmControlPlane. Use cases like this can be implemented with ClusterClass patches.
Defining variables in the ClusterClass
The following example shows how variables can be defined in the ClusterClass.
A variable definition specifies the name and the schema of a variable and if it is
required. The schema defines how a variable is defaulted and validated. It supports
a subset of the schema of CRDs. For more information please see the godoc.
The variable can then be used in a patch to set a field on a template referenced in the ClusterClass.
The selector specifies on which template the patch should be applied. jsonPatches specifies which JSON
patches should be applied to that template. In this case we set the imageRepository field of the
KubeadmControlPlaneTemplate to the value of the variable imageRepository. For more information
please see the godoc.
The controller needs to generate names for new objects when a Cluster is getting created
from a ClusterClass. These names have to be unique for each namespace. The naming
strategy enables this by concatenating the cluster name with a random suffix.
It is possible to provide a custom template for the name generation of ControlPlane, MachineDeployment
and MachinePool objects.
The generated names must comply with the RFC 1123 standard.
As a user, I may need to create a Cluster from a ClusterClass object that exists only in a different namespace. To uniquely identify the ClusterClass, a NamespacedName ref is constructed from combination of:
cluster.spec.topology.classNamespace - namespace of the ClusterClass object.
cluster.spec.topology.class - name of the ClusterClass object.
Example of the Cluster object with the name/namespace reference:
It is often desirable to restrict free cross-namespace ClusterClass access for the Cluster object. This can be implemented by defining a ValidatingAdmissionPolicy on the Cluster object.
If you want to use many variations of MachineDeployments in Clusters, you can either define
a MachineDeployment class for every variation or you can define patches and variables to
make a single MachineDeployment class more flexible. The same applies for MachinePools.
In the following example we make the instanceType of a AWSMachineTemplate customizable.
First we define the workerMachineType variable and the corresponding patch:
In the Cluster resource the workerMachineType variable can then be set cluster-wide and
it can also be overridden for an individual MachineDeployment or MachinePool.
Please note, these variables are only available when using a control plane with machines and
when patching control plane or control plane machine templates.
Please note, these variables are only available when patching the templates of a MachineDeployment
and contain the values of the current MachineDeployment topology.
Please note, these variables are only available when patching the templates of a MachineDeployment
and contain the values of the current MachineDeployment topology.
Please note, these variables are only available when patching the templates of a MachinePool
and contain the values of the current MachinePool topology.
Please note, these variables are only available when patching the templates of a MachinePool
and contain the values of the current MachinePool topology.
Builtin variables can be referenced just like regular variables, e.g.:
Builtin variables can be used to dynamically calculate image names. The version used in the patch
will always be the same as the one we set in the corresponding MachineDeployment or MachinePool
(works the same way with .builtin.controlPlane.version).
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: docker-clusterclass-v0.1.0
spec:
...
patches:
- name: customImage
description: "Sets the container image that is used for running dockerMachines."
definitions:
- selector:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: DockerMachineTemplate
matchResources:
machineDeploymentClass:
names:
- default-worker
jsonPatches:
- op: add
path: /spec/template/spec/customImage
valueFrom:
template: |
kindest/node:{{ .builtin.machineDeployment.version }}
Variables can also be objects, maps and arrays. An object is specified with the type object and
by the schemas of the fields of the object. A map is specified with the type object and the schema
of the map values. An array is specified via the type array and the schema of the array items.
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: docker-clusterclass-v0.1.0
spec:
...
variables:
- name: httpProxy
schema:
openAPIV3Schema:
type: object
properties:
# Schema of the url field.
url:
type: string
# Schema of the noProxy field.
noProxy:
type: string
- name: mdConfig
schema:
openAPIV3Schema:
type: object
additionalProperties:
# Schema of the map values.
type: object
properties:
osImage:
type: string
- name: dnsServers
schema:
openAPIV3Schema:
type: array
items:
# Schema of the array items.
type: string
Objects, maps and arrays can be used in patches either directly by referencing the variable name,
or by accessing individual fields. For example:
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: docker-clusterclass-v0.1.0
spec:
...
jsonPatches:
- op: add
path: /spec/template/spec/httpProxy/url
valueFrom:
# Use the url field of the httpProxy variable.
variable: httpProxy.url
- op: add
path: /spec/template/spec/customImage
valueFrom:
# Use the osImage field of the mdConfig variable for the current MD class.
template: "{{ (index .mdConfig .builtin.machineDeployment.class).osImage }}"
- op: add
path: /spec/template/spec/dnsServers
valueFrom:
# Use the entire dnsServers array.
variable: dnsServers
- op: add
path: /spec/template/spec/dnsServer
valueFrom:
# Use the first item of the dnsServers array.
variable: dnsServers[0]
Tips & Tricks
Complex variables can be used to make references in templates configurable, e.g. the identityRef used in AzureCluster.
Of course it’s also possible to only make the name of the reference configurable, including restricting the valid values
to a pre-defined enum.
User should be aware that the lack of the validation of users provided data could lead to problems
when those values are used in patch or when the generated templates are created (see e.g.
6135).
As a consequence we recommend avoiding this practice while we are considering alternatives to make
it explicit for the ClusterClass authors to opt-in in this feature, thus accepting the implied risks.
We already saw above that it’s possible to use variable values in JSON patches. It’s also
possible to calculate values via Go templating or to use hard-coded values.
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: docker-clusterclass-v0.1.0
spec:
...
patches:
- name: etcdImageTag
definitions:
- selector:
...
jsonPatches:
- op: add
path: /spec/template/spec/kubeadmConfigSpec/clusterConfiguration/etcd
valueFrom:
# This template is first rendered with Go templating, then parsed by
# a YAML/JSON parser and then used as value of the JSON patch.
# For example, if the variable etcdImageTag is set to `3.5.1-0` the
# .../clusterConfiguration/etcd field will be set to:
# {"local": {"imageTag": "3.5.1-0"}}
template: |
local:
imageTag: {{ .etcdImageTag }}
- name: imageRepository
definitions:
- selector:
...
jsonPatches:
- op: add
path: /spec/template/spec/kubeadmConfigSpec/clusterConfiguration/imageRepository
# This hard-coded value is used directly as value of the JSON patch.
value: "my.custom.registry"
Tips & Tricks
Templates can be used to implement defaulting behavior during JSON patch value calculation. This can be used if the simple
constant default value which can be specified in the schema is not enough.
valueFrom:
# If .vnetName is set, it is used. Otherwise, we will use `{{.builtin.cluster.name}}-vnet`.
template: "{{ if .vnetName }}{{.vnetName}}{{else}}{{.builtin.cluster.name}}-vnet{{end}}"
When writing templates, a subset of functions from the Sprig library can be used to
write expressions, e.g., {{ .name | upper }}. Only functions that are guaranteed to evaluate to the same result
for a given input are allowed (e.g. upper or max can be used, while now or randAlpha cannot be used).
Patches can also be conditionally enabled. This can be done by configuring a Go template via enabledIf.
The patch is then only applied if the Go template evaluates to true. In the following example the httpProxy
patch is only applied if the httpProxy variable is set (and not empty).
Hard-coded values can be used to test the impact of a patch during development, gradually roll out patches, etc. .
enabledIf: false
A boolean variable can be used to enable/disable a patch (or “feature”). This can have opt-in or opt-out behavior
depending on the default value of the variable.
enabledIf: "{{ .httpProxyEnabled }}"
Of course the same is possible by adding a boolean variable to a configuration object.
enabledIf: "{{ .httpProxy.enabled }}"
Builtin variables can be leveraged to apply a patch only for a specific Kubernetes version.
In some cases the ClusterClass authors want a patch to be computed according to the Kubernetes version in use.
While this is not a problem “per se” and it does not differ from writing any other patch, it is important
to keep in mind that there could be different Kubernetes version in a Cluster at any time, all of them
accessible via built in variables:
builtin.cluster.topology.version defines the Kubernetes version from cluster.topology, and it acts
as the desired Kubernetes version for the entire cluster. However, during an upgrade workflow it could happen that
some objects in the Cluster are still at the older version.
builtin.controlPlane.version, represent the desired version for the control plane object; usually this
version changes immediately after cluster.topology.version is updated (unless there are other operations
in progress preventing the upgrade to start).
builtin.machineDeployment.version, represent the desired version for each specific MachineDeployment object;
this version changes only after the upgrade for the control plane is completed, and in case of many
MachineDeployments in the same cluster, they are upgraded sequentially.
builtin.machinePool.version, represent the desired version for each specific MachinePool object;
this version changes only after the upgrade for the control plane is completed, and in case of many
MachinePools in the same cluster, they are upgraded sequentially.
This info should provide the bases for developing version-aware patches, allowing the patch author to determine when a
patch should adapt to the new Kubernetes version by choosing one of the above variables. In practice the
following rules applies to the most common use cases:
When developing a version-aware patch for the control plane, builtin.controlPlane.version must be used.
When developing a version-aware patch for MachineDeployments, builtin.machineDeployment.version must be used.
When developing a version-aware patch for MachinePools, builtin.machinePool.version must be used.
Tips & Tricks:
Sometimes users need to define variables to be used by version-aware patches, and in this case it is important
to keep in mind that there could be different Kubernetes versions in a Cluster at any time.
A simple approach to solve this problem is to define a map of version-aware variables, with the key of each item
being the Kubernetes version. Patch could then use the proper builtin variables as a lookup entry to fetch
the corresponding values for the Kubernetes version in use by each object.
JSON patches specification RFC6902 requires that the target of
add operation must exist.
As a consequence ClusterClass authors should pay special attention when the following
conditions apply in order to prevent errors when a patch is applied:
the patch tries to add a value to an array (which is a slice in the corresponding go struct)
the slice was defined with omitempty
the slice currently does not exist
A workaround in this particular case is to create the array in the patch instead of adding to the non-existing one.
When creating the slice, existing values would be overwritten so this should only be used when it does not exist.
The following example shows both cases to consider while writing a patch for adding a value to a slice.
This patch targets to add a file to the files slice of a KubeadmConfigTemplate which has omitempty set.
This patch requires the key .spec.template.spec.files to exist to succeed.
When planning a change to a ClusterClass, users should always take into consideration
how those changes might impact the existing Clusters already using the ClusterClass, if any.
There are two strategies for defining how a ClusterClass change rolls out to existing Clusters:
Roll out ClusterClass changes to existing Cluster in a controlled/incremental fashion.
Roll out ClusterClass changes to all the existing Cluster immediately.
The first strategy is the recommended choice for people starting with ClusterClass; it
requires the users to create a new ClusterClass with the expected changes, and then
rebase each Cluster to use the newly created ClusterClass.
By splitting the change to the ClusterClass and its rollout
to Clusters into separate steps the user will reduce the risk of introducing unexpected
changes on existing Clusters, or at least limit the blast radius of those changes
to a small number of Clusters already rebased (in fact it is similar to a canary deployment).
The second strategy listed above instead requires changing a ClusterClass “in place”, which can
be simpler and faster than creating a new ClusterClass. However, this approach
means that changes are immediately propagated to all the Clusters already using the
modified ClusterClass. Any operation involving many Clusters at the same time has intrinsic risks,
and it can impact heavily on the underlying infrastructure in case the operation triggers
machine rollout across the entire fleet of Clusters.
However, regardless of which strategy you are choosing to implement your changes to a ClusterClass,
please make sure to:
Understand what Compatibility Checks are and how to prevent changes
that can lead to non-functional Clusters.
If instead you are interested in understanding more about which kind of
effects you should expect on the Clusters, or if you are interested in additional details
about the internals of the topology reconciler you can start reading the notes in the
Plan ClusterClass changes documentation or looking at the reference
documentation at the end of this page.
Templates are an integral part of a ClusterClass, and thus the same considerations
described in the previous paragraph apply. When changing
a template referenced in a ClusterClass users should also always plan for how the
change should be propagated to the existing Clusters and choose the strategy that best
suits expectations.
Understand what Compatibility Checks are and how to prevent changes
that can lead to non-functional Clusters.
You can learn more about this reading the notes in the Plan ClusterClass changes documentation or
looking at the reference documentation at the end of this page.
Rebasing is an operational practice for transitioning a Cluster from one ClusterClass to another,
and the operation can be triggered by simply changing the value in Cluster.spec.topology.class.
Understand what Compatibility Checks are and how to prevent changes
that can lead to non-functional Clusters.
You can learn more about this reading the notes in the Plan ClusterClass changes documentation or
looking at the reference documentation at the end of this page.
When changing a ClusterClass, the system validates the required changes according to
a set of “compatibility rules” in order to prevent changes which would lead to a non-functional
Cluster, e.g. changing the InfrastructureProvider from AWS to Azure.
If the proposed changes are evaluated as dangerous, the operation is rejected.
For additional info see compatibility rules
defined in the ClusterClass proposal.
It is highly recommended to always generate a plan for ClusterClass changes before applying them,
no matter if you are creating a new ClusterClass and rebasing Clusters or if you are changing
your ClusterClass in place.
The output of this command will provide you all the details about how those changes would impact
Clusters, but the following notes can help you to understand what you should
expect when planning your ClusterClass changes:
Users should expect the resources in a Cluster (e.g. MachineDeployments) to behave consistently
no matter if a change is applied via a ClusterClass or directly as you do in a Cluster without
a ClusterClass. In other words, if someone changes something on a KCP object triggering a
control plane Machines rollout, you should expect the same to happen when the same change
is applied to the KCP template in ClusterClass.
User should expect the Cluster topology to change consistently irrespective of how the change has been
implemented inside the ClusterClass or applied to the ClusterClass. In other words,
if you change a template field “in place”, or if you rotate the template referenced in the
ClusterClass by pointing to a new template with the same field changed, or if you change the
same field via a patch, the effects on the Cluster are the same.
The following table documents the effects each ClusterClass change can have on a Cluster;
Similar considerations apply to changes introduced by changes in Cluster.Topology or by
changes introduced by patches.
NOTE: for people used to operating Cluster API without Cluster Class, it could also help to keep in mind that the
underlying objects like control plane and MachineDeployment act in the same way with and without a ClusterClass.
Changed field
Effects on Clusters
infrastructure.ref
Corresponding InfrastructureCluster objects are updated (in place update).
controlPlane.metadata
If labels/annotations are added, changed or deleted the ControlPlane objects are updated (in place update).
In case of KCP, corresponding controlPlane Machines, KubeadmConfigs and InfrastructureMachines are updated in-place.
controlPlane.ref
Corresponding ControlPlane objects are updated (in place update). If updating ControlPlane objects implies changes in the spec, the corresponding ControlPlane Machines are updated accordingly (rollout).
controlPlane.machineInfrastructure.ref
If the referenced template has changes only in metadata labels or annotations, the corresponding InfrastructureMachineTemplates are updated (in place update).
If the referenced template has changes in the spec: - Corresponding InfrastructureMachineTemplate are rotated (create new, delete old) - Corresponding ControlPlane objects are updated with the reference to the newly created template (in place update) - The corresponding controlPlane Machines are updated accordingly (rollout).
controlPlane.nodeDrainTimeout
If the value is changed the ControlPlane object is updated in-place.
In case of KCP, the change is propagated in-place to control plane Machines.
controlPlane.nodeVolumeDetachTimeout
If the value is changed the ControlPlane object is updated in-place.
In case of KCP, the change is propagated in-place to control plane Machines.
controlPlane.nodeDeletionTimeout
If the value is changed the ControlPlane object is updated in-place.
In case of KCP, the change is propagated in-place to control plane Machines.
workers.machineDeployments
If a new MachineDeploymentClass is added, no changes are triggered to the Clusters. If an existing MachineDeploymentClass is changed, effect depends on the type of change (see below).
workers.machineDeployments[].template.metadata
If labels/annotations are added, changed or deleted the MachineDeployment objects are updated (in place update) and corresponding worker Machines are updated (in-place).
If the referenced template has changes only in metadata labels or annotations, the corresponding BootstrapTemplates are updated (in place update).
If the referenced template has changes in the spec: - Corresponding BootstrapTemplate are rotated (create new, delete old). - Corresponding MachineDeployments objects are updated with the reference to the newly created template (in place update). - The corresponding worker machines are updated accordingly (rollout)
If the referenced template has changes only in metadata labels or annotations, the corresponding InfrastructureMachineTemplates are updated (in place update).
If the referenced template has changes in the spec: - Corresponding InfrastructureMachineTemplate are rotated (create new, delete old). - Corresponding MachineDeployments objects are updated with the reference to the newly created template (in place update). - The corresponding worker Machines are updated accordingly (rollout)
The topology reconciler enforces values defined in the ClusterClass templates into the topology
owned objects in a Cluster.
More specifically, the topology controller uses Server Side Apply
to write/patch topology owned objects; using SSA allows other controllers to co-author the generated objects,
like e.g. adding info for subnets in CAPA.
A corollary of the behaviour described above is that it is technically possible to change fields in the object
which are not derived from the templates and patches, but we advise against using the possibility
or making ad-hoc changes in generated objects unless otherwise needed for a workaround. It is always
preferable to improve ClusterClasses by supporting new Cluster variants in a reusable way.
The spec.topology field added to the Cluster object as part of ClusterClass allows changes made on the Cluster to be propagated across all relevant objects. This means the Cluster object can be used as a single point of control for making changes to objects that are part of the Cluster, including the ControlPlane and MachineDeployments.
Using a managed topology the operation to upgrade a Kubernetes cluster is a one-touch operation.
Let’s assume we have created a CAPD cluster with ClusterClass and specified Kubernetes v1.21.2 (as documented in the Quick Start guide). Specifying the version is done when running clusterctl generate cluster. Looking at the cluster, the version of the control plane and the MachineDeployments is v1.21.2.
> kubectl get kubeadmcontrolplane,machinedeployments
NAME CLUSTER INITIALIZED API SERVER AVAILABLE REPLICAS READY UPDATED UNAVAILABLE AGE VERSION
kubeadmcontrolplane.controlplane.cluster.x-k8s.io/clusterclass-quickstart-XXXX clusterclass-quickstart true true 1 1 1 0 2m21s v1.21.2
NAME CLUSTER REPLICAS READY UPDATED UNAVAILABLE PHASE AGE VERSION
machinedeployment.cluster.x-k8s.io/clusterclass-quickstart-linux-workers-XXXX clusterclass-quickstart 1 1 1 0 Running 2m21s v1.21.2
To update the Cluster the only change needed is to the version field under spec.topology in the Cluster object.
Important Note: A +2 minor Kubernetes version upgrade is not allowed in Cluster Topologies. This is to align with existing control plane providers, like KubeadmControlPlane provider, that limit a +2 minor version upgrade. Example: Upgrading from 1.21.2 to 1.23.0 is not allowed.
The upgrade will take some time to roll out as it will take place machine by machine with older versions of the machines only being removed after healthy newer versions come online.
To watch the update progress run:
watch kubectl get kubeadmcontrolplane,machinedeployments
After a few minutes the upgrade will be complete and the output will be similar to:
NAME CLUSTER INITIALIZED API SERVER AVAILABLE REPLICAS READY UPDATED UNAVAILABLE AGE VERSION
kubeadmcontrolplane.controlplane.cluster.x-k8s.io/clusterclass-quickstart-XXXX clusterclass-quickstart true true 1 1 1 0 7m29s v1.22.0
NAME CLUSTER REPLICAS READY UPDATED UNAVAILABLE PHASE AGE VERSION
machinedeployment.cluster.x-k8s.io/clusterclass-quickstart-linux-workers-XXXX clusterclass-quickstart 1 1 1 0 Running 7m29s v1.22.0
When using a managed topology scaling of MachineDeployments, both up and down, should be done through the Cluster topology.
Assume we have created a CAPD cluster with ClusterClass and Kubernetes v1.23.3 (as documented in the Quick Start guide). Initially we should have a MachineDeployment with 3 replicas. Running
kubectl get machinedeployments
Will give us:
NAME CLUSTER REPLICAS READY UPDATED UNAVAILABLE PHASE AGE VERSION
machinedeployment.cluster.x-k8s.io/capi-quickstart-md-0-XXXX capi-quickstart 3 3 3 0 Running 21m v1.23.3
We can scale up or down this MachineDeployment through the Cluster object by changing the replicas field under /spec/topology/workers/machineDeployments/0/replicas
The 0 in the path refers to the position of the target MachineDeployment in the list of our Cluster topology. As we only have one MachineDeployment we’re targeting the first item in the list under /spec/topology/workers/machineDeployments/.
After a minute the MachineDeployment will have scaled down to 1 replica:
NAME CLUSTER REPLICAS READY UPDATED UNAVAILABLE PHASE AGE VERSION
capi-quickstart-md-0-XXXXX capi-quickstart 1 1 1 0 Running 25m v1.23.3
As well as scaling a MachineDeployment, Cluster operators can edit the labels and annotations applied to a running MachineDeployment using the Cluster topology as a single point of control.
MachineDeployments in a managed Cluster are defined in the Cluster’s topology. Cluster operators can add a MachineDeployment to a living Cluster by adding it to the cluster.spec.topology.workers.machineDeployments field.
Assume we have created a CAPD cluster with ClusterClass and Kubernetes v1.23.3 (as documented in the Quick Start guide). Initially we should have a single MachineDeployment with 3 replicas. Running
kubectl get machinedeployments
Will give us:
NAME CLUSTER REPLICAS READY UPDATED UNAVAILABLE PHASE AGE VERSION
machinedeployment.cluster.x-k8s.io/capi-quickstart-md-0-XXXX capi-quickstart 3 3 3 0 Running 21m v1.23.3
A new MachineDeployment can be added to the Cluster by adding a new MachineDeployment spec under /spec/topology/workers/machineDeployments/. To do so we can patch our Cluster with:
After a minute to scale the new MachineDeployment we get:
NAME CLUSTER REPLICAS READY UPDATED UNAVAILABLE PHASE AGE VERSION
capi-quickstart-md-0-XXXX capi-quickstart 1 1 1 0 Running 39m v1.23.3
capi-quickstart-second-deployment-XXXX capi-quickstart 1 1 1 0 Running 99s v1.23.3
Our second deployment uses the same underlying MachineDeployment class default-worker as our initial deployment. In this case they will both have exactly the same underlying machine templates. In order to modify the templates MachineDeployments are based on take a look at Changing a ClusterClass.
A similar process as that described here - removing the MachineDeployment from cluster.spec.topology.workers.machineDeployments - can be used to delete a running MachineDeployment from an active Cluster.
When using a managed topology scaling of ControlPlane Machines, where the Cluster is using a topology that includes ControlPlane MachineInfrastructure, should be done through the Cluster topology.
This is done by changing the ControlPlane replicas field at /spec/topology/controlPlane/replica in the Cluster object. The command is:
As well as scaling a ControlPlane, Cluster operators can edit the labels and annotations applied to a running ControlPlane using the Cluster topology as a single point of control.
A ClusterClass can use variables and patches in order to allow flexible customization of Clusters derived from a ClusterClass. Variable definition allows two or more Cluster topologies derived from the same ClusterClass to have different specs, with the differences controlled by variables in the Cluster topology.
Assume we have created a CAPD cluster with ClusterClass and Kubernetes v1.23.3 (as documented in the Quick Start guide). Our Cluster has a variable etcdImageTag as defined in the ClusterClass. The variable is not set on our Cluster. Some variables, depending on their definition in a ClusterClass, may need to be specified by the Cluster operator for every Cluster created using a given ClusterClass.
In order to specify the value of a variable all we have to do is set the value in the Cluster topology.
We can see the current unset variable with:
kubectl get cluster capi-quickstart -o jsonpath='{.spec.topology.variables[1]}'
Which will return something like:
{"name":"etcdImageTag","value":""}
In order to run a different version of etcd in new ControlPlane machines - the part of the spec this variable sets - change the value using the below patch:
Retrieving the variable value from the Cluster object, with kubectl get cluster capi-quickstart -o jsonpath='{.spec.topology.variables[1]}' we can see:
{"name":"etcdImageTag","value":"3.5.0"}
Note: Changing the etcd version may have unintended impacts on a running Cluster. For safety the cluster should be reapplied after running the above variable patch.
To perform more significant changes using a Cluster as a single point of control, it may be necessary to change the ClusterClass that the Cluster is based on. This is done by changing the class referenced in /spec/topology/class.
To read more about changing an underlying class please refer to ClusterClass rebase.
Users should always aim at ensuring the stability of the Cluster and of the applications hosted on it while
using spec.topology as a single point of control for making changes to the objects that are part of the Cluster.
Following recommendation apply:
If possible, avoid concurrent changes to control-plane and/or MachineDeployments to prevent
excessive turnover on the underlying infrastructure or bottlenecks in the Cluster trying to move workloads
from one machine to the other.
Keep machine labels and annotation stable, because changing those values requires machines rollouts;
also, please note that machine labels and annotation are not propagated to Kubernetes nodes; see
metadata propagation.
While upgrading a Cluster, if possible avoid any other concurrent change to the Cluster; please note
that you can rely on version-aware patches to ensure
the Cluster adapts to the new Kubernetes version in sync with the upgrade workflow.
For more details about how changes can affect a Cluster, please look at reference.
There are some special considerations for ClusterClass regarding Cluster API upgrades when the upgrade includes a bump
of the apiVersion of infrastructure, bootstrap or control plane provider CRDs.
The recommended approach is to first upgrade Cluster API and then update the apiVersions in the ClusterClass references afterwards.
By following above steps, there won’t be any disruptions of the reconciliation as the Cluster topology controller is able to reconcile the Cluster
even with the old apiVersions in the ClusterClass.
Note: The apiVersions in ClusterClass cannot be updated before Cluster API because the new apiVersions don’t exist in
the management cluster before the Cluster API upgrade.
In general the Cluster topology controller always uses exactly the versions of the CRDs referenced in the ClusterClass.
This means in the following example the Cluster topology controller will always use v1beta1 when reconciling/applying
patches for the infrastructure ref, even if the DockerClusterTemplate already has a v1beta2 apiVersion.
The Runtime SDK feature provides an extensibility mechanism that allows systems, products, and services built on top of Cluster API to hook into a workload cluster’s lifecycle.
Feature gate name: RuntimeSDK
Variable name to enable/disable the feature gate: EXP_RUNTIME_SDK
As a developer building systems on top of Cluster API, if you want to hook into the Cluster’s lifecycle via
a Runtime Hook, you have to implement a Runtime Extension handling requests according to the
OpenAPI specification for the Runtime Hook you are interested in.
Runtime Extensions by design are very powerful and flexible, however given that with great power comes
great responsibility, a few key consideration should always be kept in mind (more details in the following sections):
Runtime Extensions are components that should be designed, written and deployed with great caution given that they
can affect the proper functioning of the Cluster API runtime.
Cluster administrators should carefully vet any Runtime Extension registration, thus preventing malicious components
from being added to the system.
Please note that following similar practices is already commonly accepted in the Kubernetes ecosystem for
Kubernetes API server admission webhooks. Runtime Extensions share the same foundation and most of the same
considerations/concerns apply.
As mentioned above as a developer building systems on top of Cluster API, if you want to hook in the Cluster’s
lifecycle via a Runtime Extension, you have to implement an HTTPS server handling a discovery request and a set
of additional requests according to the OpenAPI specification for the Runtime Hook you are interested in.
The following shows a minimal example of a Runtime Extension server implementation:
package main
import (
"context"
"flag"
"net/http"
"os"
"github.com/spf13/pflag"
cliflag "k8s.io/component-base/cli/flag"
"k8s.io/component-base/logs"
logsv1 "k8s.io/component-base/logs/api/v1"
"k8s.io/klog/v2"
ctrl "sigs.k8s.io/controller-runtime"
runtimecatalog "sigs.k8s.io/cluster-api/exp/runtime/catalog"
runtimehooksv1 "sigs.k8s.io/cluster-api/exp/runtime/hooks/api/v1alpha1"
"sigs.k8s.io/cluster-api/exp/runtime/server"
)
var (
// catalog contains all information about RuntimeHooks.
catalog = runtimecatalog.New()
// Flags.
profilerAddress string
webhookPort int
webhookCertDir string
logOptions = logs.NewOptions()
)
func init() {
// Adds to the catalog all the RuntimeHooks defined in cluster API.
_ = runtimehooksv1.AddToCatalog(catalog)
}
// InitFlags initializes the flags.
func InitFlags(fs *pflag.FlagSet) {
// Initialize logs flags using Kubernetes component-base machinery.
logsv1.AddFlags(logOptions, fs)
// Add test-extension specific flags
fs.StringVar(&profilerAddress, "profiler-address", "",
"Bind address to expose the pprof profiler (e.g. localhost:6060)")
fs.IntVar(&webhookPort, "webhook-port", 9443,
"Webhook Server port")
fs.StringVar(&webhookCertDir, "webhook-cert-dir", "/tmp/k8s-webhook-server/serving-certs/",
"Webhook cert dir.")
}
func main() {
// Creates a logger to be used during the main func.
setupLog := ctrl.Log.WithName("setup")
// Initialize and parse command line flags.
InitFlags(pflag.CommandLine)
pflag.CommandLine.SetNormalizeFunc(cliflag.WordSepNormalizeFunc)
pflag.CommandLine.AddGoFlagSet(flag.CommandLine)
// Set log level 2 as default.
if err := pflag.CommandLine.Set("v", "2"); err != nil {
setupLog.Error(err, "Failed to set default log level")
os.Exit(1)
}
pflag.Parse()
// Validates logs flags using Kubernetes component-base machinery and applies them
if err := logsv1.ValidateAndApply(logOptions, nil); err != nil {
setupLog.Error(err, "Unable to start extension")
os.Exit(1)
}
// Add the klog logger in the context.
ctrl.SetLogger(klog.Background())
// Initialize the golang profiler server, if required.
if profilerAddress != "" {
klog.Infof("Profiler listening for requests at %s", profilerAddress)
go func() {
klog.Info(http.ListenAndServe(profilerAddress, nil))
}()
}
// Create a http server for serving runtime extensions
webhookServer, err := server.New(server.Options{
Catalog: catalog,
Port: webhookPort,
CertDir: webhookCertDir,
})
if err != nil {
setupLog.Error(err, "Error creating webhook server")
os.Exit(1)
}
// Register extension handlers.
if err := webhookServer.AddExtensionHandler(server.ExtensionHandler{
Hook: runtimehooksv1.BeforeClusterCreate,
Name: "before-cluster-create",
HandlerFunc: DoBeforeClusterCreate,
}); err != nil {
setupLog.Error(err, "Error adding handler")
os.Exit(1)
}
if err := webhookServer.AddExtensionHandler(server.ExtensionHandler{
Hook: runtimehooksv1.BeforeClusterUpgrade,
Name: "before-cluster-upgrade",
HandlerFunc: DoBeforeClusterUpgrade,
}); err != nil {
setupLog.Error(err, "Error adding handler")
os.Exit(1)
}
// Setup a context listening for SIGINT.
ctx := ctrl.SetupSignalHandler()
// Start the https server.
setupLog.Info("Starting Runtime Extension server")
if err := webhookServer.Start(ctx); err != nil {
setupLog.Error(err, "Error running webhook server")
os.Exit(1)
}
}
func DoBeforeClusterCreate(ctx context.Context, request *runtimehooksv1.BeforeClusterCreateRequest, response *runtimehooksv1.BeforeClusterCreateResponse) {
log := ctrl.LoggerFrom(ctx)
log.Info("BeforeClusterCreate is called")
// Your implementation
}
func DoBeforeClusterUpgrade(ctx context.Context, request *runtimehooksv1.BeforeClusterUpgradeRequest, response *runtimehooksv1.BeforeClusterUpgradeResponse) {
log := ctrl.LoggerFrom(ctx)
log.Info("BeforeClusterUpgrade is called")
// Your implementation
}
Please note that a Runtime Extension server can serve multiple Runtime Hooks (in the example above
BeforeClusterCreate and BeforeClusterUpgrade) at the same time. Each of them are handled at a different path, like the
Kubernetes API server does for different API resources. The exact format of those paths is handled by the server
automatically in accordance to the OpenAPI specification of the Runtime Hooks.
There is an additional Discovery endpoint which is automatically served by the Server. The Discovery endpoint
returns a list of extension handlers to inform Cluster API which Runtime Hooks are implemented by this
Runtime Extension server.
Please note that Cluster API is only able to enforce the correct request and response types as defined by a Runtime Hook version.
Developers are fully responsible for all other elements of the design of a Runtime Extension implementation, including:
To choose which programming language to use; please note that Golang is the language of choice, and we are not planning
to test or provide tooling and libraries for other languages. Nevertheless, given that we rely on Open API and plain
HTTPS calls, other languages should just work but support will be provided at best effort.
To choose if a dedicated or a shared HTTPS Server is used for the Runtime Extension (it can be e.g. also used to serve a
metric endpoint).
When using Golang the Runtime Extension developer can benefit from the following packages (provided by the
sigs.k8s.io/cluster-api module) as shown in the example above:
exp/runtime/hooks/api/v1alpha1 contains the Runtime Hook Golang API types, which are also used to generate the
OpenAPI specification.
exp/runtime/catalog provides the Catalog object to register Runtime Hook definitions. The Catalog is then
used by the server package to handle requests. Catalog is similar to the runtime.Scheme of the
k8s.io/apimachinery/pkg/runtime package, but it is designed to store Runtime Hook registrations.
exp/runtime/server provides a Server object which makes it easy to implement a Runtime Extension server.
The Server will automatically handle tasks like Marshalling/Unmarshalling requests and responses. A Runtime
Extension developer only has to implement a strongly typed function that contains the actual logic.
Runtime Extension processing adds to reconcile durations of Cluster API controllers. They should respond to requests
as quickly as possible, typically in milliseconds. Runtime Extension developers can decide how long the Cluster API Runtime
should wait for a Runtime Extension to respond before treating the call as a failure (max is 30s) by returning the timeout
during discovery. Of course a Runtime Extension can trigger long-running tasks in the background, but they shouldn’t block
synchronously.
Runtime Extension failure could result in errors in handling the workload clusters lifecycle, and so the implementation
should be robust, have proper error handling, avoid panics, etc. Failure policies can be set up to mitigate the
negative impact of a Runtime Extension on the Cluster API Runtime, but this option can’t be used in all cases
(see Error Management).
A Runtime Hook can be defined as “blocking” - e.g. the BeforeClusterUpgrade hook allows a Runtime Extension
to prevent the upgrade from starting. A Runtime Extension registered for the BeforeClusterUpgrade hook
can block by returning a non-zero retryAfterSeconds value. Following consideration apply:
The system might decide to retry the same Runtime Extension even before the retryAfterSeconds period expires,
e.g. due to other changes in the Cluster, so retryAfterSeconds should be considered as an approximate maximum
time before the next reconcile.
If there is more than one Runtime Extension registered for the same Runtime Hook and more than one returns
retryAfterSeconds, the shortest non-zero value will be used.
If there is more than one Runtime Extension registered for the same Runtime Hook and at least one returns
retryAfterSeconds, all Runtime Extensions will be called again.
Detailed description of what “blocking” means for each specific Runtime Hooks is documented case by case
in the hook-specific implementation documentation (e.g. Implementing Lifecycle Hook Runtime Extensions).
It is recommended that Runtime Extensions should avoid side effects if possible, which means they should operate
only on the content of the request sent to them, and not make out-of-band changes. If side effects are required,
rules defined in the following sections apply.
An idempotent Runtime Extension is able to succeed even in case it has already been completed before (the Runtime
Extension checks current state and changes it only if necessary). This is necessary because a Runtime Extension
may be called many times after it already succeeded because other Runtime Extensions for the same hook may not
succeed in the same reconcile.
A practical example that explains why idempotence is relevant is the fact that extensions could be called more
than once for the same lifecycle transition, e.g.
Two Runtime Extensions are registered for the BeforeClusterUpgrade hook.
Before a Cluster upgrade is started both extensions are called, but one of them temporarily blocks the operation
by asking to retry after 30 seconds.
After 30 seconds the system retries the lifecycle transition, and both extensions are called again to re-evaluate
if it is now possible to proceed with the Cluster upgrade.
Each Runtime Extension should accomplish its task without depending on other Runtime Extensions. Introducing
dependencies across Runtime Extensions makes the system fragile, and it is probably a consequence of poor
“Separation of Concerns” between extensions.
A deterministic Runtime Extension is implemented in such a way that given the same input it will always return
the same output.
Some Runtime Hooks, e.g. like external patches, might explicitly request for corresponding Runtime Extensions
to support this property. But we encourage developers to follow this pattern more generally given that it fits
well with practices like unit testing and generally makes the entire system more predictable and easier to troubleshoot.
RuntimeExtension authors should be aware that error messages are surfaced as a conditions in Kubernetes resources
and recorded in Cluster API controller’s logs. As a consequence:
Error message must not contain any sensitive information.
Error message must be deterministic, and must avoid to including timestamps or values changing at every call.
Error message must not contain external errors when it’s not clear if those errors are deterministic (e.g. errors return from cloud APIs).
To register your runtime extension apply the ExtensionConfig resource in the management cluster, including your CA
certs, ClusterIP service associated with the app and namespace, and the target namespace for the given extension. Once
created, the extension will detect the associated service and discover the associated Hooks. For clarification, you can
check the status of the ExtensionConfig. Below is an example of ExtensionConfig -
apiVersion: runtime.cluster.x-k8s.io/v1alpha1
kind: ExtensionConfig
metadata:
annotations:
runtime.cluster.x-k8s.io/inject-ca-from-secret: default/test-runtime-sdk-svc-cert
name: test-runtime-sdk-extensionconfig
spec:
clientConfig:
service:
name: test-runtime-sdk-svc
namespace: default # Note: this assumes the test extension get deployed in the default namespace
port: 443
namespaceSelector:
matchExpressions:
- key: kubernetes.io/metadata.name
operator: In
values:
- default # Note: this assumes the test extension is used by Cluster in the default namespace only
Settings can be added to the ExtensionConfig object in the form of a map with string keys and values. These settings are
sent with each request to hooks registered by that ExtensionConfig. Extension developers can implement behavior in their
extensions to alter behavior based on these settings. Settings should be well documented by extension developers so that
ClusterClass authors can understand usage and expected behaviour.
Settings can be provided for individual external patches by providing them in the ClusterClass .spec.patches[*].external.settings.
This can be used to overwrite settings at the ExtensionConfig level for that patch.
In case a Runtime Extension returns an error, the error will be handled according to the corresponding failure policy
defined in the response of the Discovery call.
If the failure policy is Ignore the error is going to be recorded in the controller’s logs, but the processing
will continue. However we recognize that this failure policy cannot be used in most of the use cases because Runtime
Extension implementers want to ensure that the task implemented by an extension is completed before continuing with
the cluster’s lifecycle.
If instead the failure policy is Fail the system will retry the operation until it passes. The following general
considerations apply:
It is the responsibility of Cluster API components to surface Runtime Extension errors using conditions.
Operations will be retried with an exponential backoff or whenever the state of a Cluster changes (we are going to rely
on controller runtime exponential backoff/watches).
If there is more than one Runtime Extension registered for the same Runtime Hook and at least one of them fails,
all the registered Runtime Extension will be retried. See Idempotence
Additional considerations about errors that apply only to a specific Runtime Hook will be documented in the hook-specific
implementation documentation.
Make sure to add the ExtensionConfig object to the YAML manifest used to deploy the runtime extensions (see Extensionsconfig for more details).
After you implemented and deployed a Runtime Extension you can manually test it by sending HTTP requests.
This can be for example done via kubectl:
Via kubectl create --raw:
# Send a Discovery Request to the webhook-service in namespace default with protocol https on port 443:
kubectl create --raw '/api/v1/namespaces/default/services/https:webhook-service:443/proxy/hooks.runtime.cluster.x-k8s.io/v1alpha1/discovery' \
-f <(echo '{"apiVersion":"hooks.runtime.cluster.x-k8s.io/v1alpha1","kind":"DiscoveryRequest"}') | jq
Via kubectl proxy and curl:
# Open a proxy with kubectl and then use curl to send the request
## First terminal:
kubectl proxy
## Second terminal:
curl -X 'POST' 'http://127.0.0.1:8001/api/v1/namespaces/default/services/https:webhook-service:443/proxy/hooks.runtime.cluster.x-k8s.io/v1alpha1/discovery' \
-d '{"apiVersion":"hooks.runtime.cluster.x-k8s.io/v1alpha1","kind":"DiscoveryRequest"}' | jq
For more details about the API of the Runtime Extensions please see .
For more details on proxy support please see Proxies in Kubernetes.
All guidelines defined in Implementing Runtime Extensions apply to the
implementation of Runtime Extensions for lifecycle hooks as well.
In summary, Runtime Extensions are components that should be designed, written and deployed with great caution given
that they can affect the proper functioning of the Cluster API runtime. A poorly implemented Runtime Extension could
potentially block lifecycle transitions from happening.
Following recommendations are especially relevant:
This hook is called after the Cluster object has been created by the user, immediately before all the objects which
are part of a Cluster topology(*) are going to be created. Runtime Extension implementers can use this hook to
determine/prepare add-ons for the Cluster and block the creation of those objects until everything is ready.
apiVersion: hooks.runtime.cluster.x-k8s.io/v1alpha1
kind: BeforeClusterCreateResponse
status: Success # or Failure
message: "error message if status == Failure"
retryAfterSeconds: 10
For additional details, you can see the full schema in .
(*) The objects which are part of a Cluster topology are the infrastructure Cluster, the Control Plane, the
MachineDeployments and the templates derived from the ClusterClass.
This hook is called after the Control Plane for the Cluster is marked as available for the first time. Runtime Extension
implementers can use this hook to execute tasks, for example component installation on workload clusters, that are only
possible once the Control Plane is available. This hook does not block any further changes to the Cluster.
This hook is called after the Cluster object has been updated with a new spec.topology.version by the user, and
immediately before the new version is going to be propagated to the control plane (*). Runtime Extension implementers
can use this hook to execute pre-upgrade add-on tasks and block upgrades of the ControlPlane and Workers.
Note: While the upgrade is blocked changes made to the Cluster Topology will be delayed propagating to the underlying
objects while the object is waiting for upgrade. Example: modifying ControlPlane/MachineDeployments (think scale up),
or creating new MachineDeployments will be delayed until the target ControlPlane/MachineDeployment is ready to pick up the upgrade.
This ensures that the ControlPlane and MachineDeployments do not perform a rollout prematurely while waiting to be rolled out again for the version upgrade (no double rollouts).
This also ensures that any version specific changes are only pushed to the underlying objects also at the correct version.
apiVersion: hooks.runtime.cluster.x-k8s.io/v1alpha1
kind: BeforeClusterUpgradeResponse
status: Success # or Failure
message: "error message if status == Failure"
retryAfterSeconds: 10
For additional details, you can see the full schema in .
(*) Under normal circumstances spec.topology.version gets propagated to the control plane immediately; however
if previous upgrades or worker machine rollouts are still in progress, the system waits for those operations
to complete before starting the new upgrade.
This hook is called after the control plane has been upgraded to the version specified in spec.topology.version,
and immediately before the new version is going to be propagated to the MachineDeployments of the Cluster.
Runtime Extension implementers can use this hook to execute post-upgrade add-on tasks and block upgrades to workers
until everything is ready.
Note: While the MachineDeployments upgrade is blocked changes made to existing MachineDeployments and creating new MachineDeployments
will be delayed while the object is waiting for upgrade. Example: modifying MachineDeployments (think scale up),
or creating new MachineDeployments will be delayed until the target MachineDeployment is ready to pick up the upgrade.
This ensures that the MachineDeployments do not perform a rollout prematurely while waiting to be rolled out again for the version upgrade (no double rollouts).
This also ensures that any version specific changes are only pushed to the underlying objects also at the correct version.
This hook is called after the Cluster, control plane and workers have been upgraded to the version specified in
spec.topology.version. Runtime Extensions implementers can use this hook to execute post-upgrade add-on tasks.
This hook does not block any further changes or upgrades to the Cluster.
This hook is called after the Cluster deletion has been triggered by the user and immediately before the topology
of the Cluster is going to be deleted. Runtime Extension implementers can use this hook to execute
cleanup tasks for the add-ons and block deletion of the Cluster and descendant objects until everything is ready.
Inline patches are easier when getting started with ClusterClass as they are built into
the Cluster API core controller, no external component have to be developed and managed.
External patches have the following advantages:
External patches can be individually written, unit tested and released/versioned.
External patches can leverage the full feature set of a programming language and
are thus not limited to the capabilities of JSON patches and Go templating.
External patches can use external data (e.g. from cloud APIs) during patch generation.
External patches can be easily reused across ClusterClasses.
The DiscoverVariables hook can be used to supply variable definitions for use in external patches. These variable definitions are added to
the status of any applicable ClusterClasses. Clusters using the ClusterClass can then set values for those variables.
External variable definitions are discovered by calling the DiscoverVariables runtime hook. This hook is called from the ClusterClass reconciler.
Once discovered the variable definitions are validated and stored in ClusterClass status.
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
# metadata
spec:
# Inline variable definitions
variables:
# This variable is unique and can be accessed globally.
- name: no-proxy
required: true
schema:
openAPIV3Schema:
type: string
default: "internal.com"
example: "internal.com"
description: "comma-separated list of machine or domain names excluded from using the proxy."
# This variable is also defined by an external DiscoverVariables hook.
- name: http-proxy
schema:
openAPIV3Schema:
type: string
default: "proxy.example.com"
example: "proxy.example.com"
description: "proxy for http calls."
# External patch definitions.
patches:
- name: lbImageRepository
external:
generateExtension: generate-patches.k8s-upgrade-with-runtimesdk
validateExtension: validate-topology.k8s-upgrade-with-runtimesdk
## Call variable discovery for this patch.
discoverVariablesExtension: discover-variables.k8s-upgrade-with-runtimesdk
status:
# observedGeneration is used to check that the current version of the ClusterClass is the same as that when the Status was previously written.
# if metadata.generation isn't the same as observedGeneration Cluster using the ClusterClass should not reconcile.
observedGeneration: xx
# variables contains a list of all variable definitions, both inline and from external patches, that belong to the ClusterClass.
variables:
- name: no-proxy
definitions:
- from: inline
required: true
schema:
openAPIV3Schema:
type: string
default: "internal.com"
example: "internal.com"
description: "comma-separated list of machine or domain names excluded from using the proxy."
- name: http-proxy
# definitionsConflict is true if there are non-equal definitions for a variable.
# Note: This conflict has to be resolved, until then corresponding Clusters are not reconciled.
definitionsConflict: true
definitions:
- from: inline
schema:
openAPIV3Schema:
type: string
default: "proxy.example.com"
example: "proxy.example.com"
description: "proxy for http calls."
- from: lbImageRepository
schema:
openAPIV3Schema:
type: string
default: "different.example.com"
example: "different.example.com"
description: "proxy for http calls."
Variable definitions can be inline in the ClusterClass or from any number of external DiscoverVariables hooks. The source
of a variable definition is recorded in the from field in ClusterClass .status.variables.
Variables that are defined by an external DiscoverVariables hook will have the name of the patch they are associated with as the value of from.
Variables that are defined in the ClusterClass .spec.variables will have inline as the value of from.
Note: inline is a reserved name for patches. It cannot be used as the name of an external patch to avoid conflicts.
If all variables that share a name have equivalent schemas the variable definitions are not in conflict. The CAPI components will
consider variable definitions to be equivalent when they share a name and their schema is exactly equal. If variables are in conflict
the VariablesReconciled will be set to false and the conflict has to be resolved. While there are variable conflicts, corresponding
Clusters will not be reconciled.
Note: We enforce that variable conflicts have to be resolved by ClusterClass authors, so that defining Cluster topology is as simply as possible for end users.
In general a single external patch extension is simpler than many, as only one extension
then has to be built, deployed and managed.
A single extension also requires less HTTP round-trips between the CAPI controller and the extension(s).
With a single extension it is still possible to implement multiple logical features using different variables.
When implementing multiple logical features in one extension it’s recommended that they can be conditionally
enabled/disabled via variables (either via certain values or by their existence).
Conway’s law might make it not feasible in large organizations
to use a single extension. In those cases it’s important that boundaries between extensions are clearly defined.
For general Runtime Extension developer guidelines please refer to the guidelines in Implementing Runtime Extensions.
This section outlines considerations specific to Topology Mutation hooks.
Input validation: An External Patch Extension must always validate its input, i.e. it must validate that
all variables exist, have the right type and it must validate the kind and apiVersion of the templates which
should be patched.
Timeouts: As External Patch Extensions are called during each Cluster topology reconciliation, they must
respond as fast as possible (<=200ms) to avoid delaying individual reconciles and congestion.
Availability: An External Patch Extension must be always available, otherwise Cluster topologies won’t be
reconciled anymore.
Side Effects: An External Patch Extension must not make out-of-band changes. If necessary external data can
be retrieved, but be aware of performance impact.
Deterministic results: For a given request (a set of templates and variables) an External Patch Extension must
always return the same response (a set of patches). Otherwise the Cluster topology will never reach a stable state.
Idempotence: An External Patch Extension must only return patches if changes to the templates are required,
i.e. unnecessary patches when the template is already in the desired state must be avoided.
Avoid Dependencies: An External Patch Extension must be independent of other External Patch Extensions. However
if dependencies cannot be avoided, it is possible to control the order in which patches are executed via the ClusterClass.
Error messages: For a given request (a set of templates and variables) an External Patch Extension must
always return the same error message. Otherwise the system might become unstable due to controllers being overloaded
by continuous changes to Kubernetes resources as these messages are reported as conditions. See error messages.
Distinctive variable names: Names should be carefully chosen, and if possible generic names should be avoided.
Using a generic name could lead to conflicts if the variables defined for this patch are used in combination with other
patches providing variables with the same name.
Avoid breaking changes to variable definitions: Changing a variable definition can lead to problems on existing
clusters because reconciliation will stop if variable values do not match the updated definition. When more than one variable
with the same name is defined, changes to variable definitions can require explicit values for each patch.
Updates to the variable definition should be carefully evaluated, and very well documented in extension release notes,
so ClusterClass authors can evaluate impacts of changes before performing an upgrade.
A GeneratePatches call generates patches for the entire Cluster topology. Accordingly the request contains all
templates, the global variables and the template-specific variables. The response contains generated patches.
Generating patches for a Cluster topology is done via a single call to allow External Patch Extensions a
holistic view of the entire Cluster topology. Additionally this allows us to reduce the number of round-trips.
Each item in the request will contain the template as a raw object. Additionally information about where
the template is used is provided via holderReference.
The response contains patches instead of full objects to reduce the payload.
Templates in the request and patches in the response will be correlated via UIDs.
Like inline patches, external patches are only allowed to change fields in spec.template.spec.
apiVersion: hooks.runtime.cluster.x-k8s.io/v1alpha1
kind: GeneratePatchesResponse
status: Success # or Failure
message: "error message if status == Failure"
items:
- uid: 7091de79-e26c-4af5-8be3-071bc4b102c9
patchType: JSONPatch
patch: <JSON-patch>
For additional details, you can see the full schema in .
We are considering to introduce a library to facilitate development of External Patch Extensions. It would provide capabilities like:
Accessing builtin variables
Extracting certain templates from a GeneratePatches request (e.g. all bootstrap templates)
If you are interested in contributing to this library please reach out to the maintainer team or
feel free to open an issue describing your idea or use case.
A ValidateTopology call validates the topology after all patches have been applied. The request contains all
templates of the Cluster topology, the global variables and the template-specific variables. The response
contains the result of the validation.
The request is the same as the GeneratePatches request except it doesn’t have uid fields. We don’t
need them as we don’t have to correlate patches in the response.
There are some special considerations regarding Cluster API upgrades when the upgrade includes a bump
of the apiVersion of infrastructure, bootstrap or control plane provider CRDs.
When calling external patches the Cluster topology controller is always sending the templates in the apiVersion of the references
in the ClusterClass.
While inline patches are always referring to one specific apiVersion, external patch implementations are more flexible. They can
be written in a way that they are able to handle multiple apiVersions of a CRD. This can be done by calculating patches differently
depending on which apiVersion is received by the external patch implementation.
This allows users more flexibility during Cluster API upgrades:
Variant 1: External patch implementation supporting two apiVersions at the same time
Update Cluster API
Update the external patch implementation to be able to handle custom resources with the old and the new apiVersion
Update the references in ClusterClasses to use the new apiVersion
Note In this variant it doesn’t matter if Cluster API or the external patch implementation is updated first.
Variant 2: Deploy an additional instance of the external patch implementation which can handle the new apiVersion
Upgrade Cluster API
Deploy the new external patch implementation which is able to handle the new apiVersion
Update ClusterClasses to use the new apiVersion and the new external patch implementation
Remove the old external patch implementation as it’s not used anymore
Note In this variant it doesn’t matter if Cluster API is updated or the new external patch implementation is deployed first.
Cluster API requires that each Runtime Extension must be deployed using an endpoint accessible from the Cluster API
controllers. The recommended deployment model is to deploy a Runtime Extension in the management cluster by:
Packing the Runtime Extension in a container image.
Using a Kubernetes Deployment to run the above container inside the Management Cluster.
Using a Cluster IP Service to make the Runtime Extension instances accessible via a stable DNS name.
Using a cert-manager generated Certificate to protect the endpoint.
Register the Runtime Extension using ExtensionConfig.
For an example, please see our test extension
which follows, as closely as possible, the kubebuilder setup used for controllers in Cluster API.
There are a set of important guidelines that must be considered while choosing the deployment method:
It is recommended that Runtime Extensions should leverage some form of load-balancing, to provide high availability
and performance benefits. You can run multiple Runtime Extension servers behind a Kubernetes Service to leverage the
load-balancing that services support.
The security model for each Runtime Extension should be carefully defined, similar to any other application deployed
in the Cluster. If the Runtime Extension requires access to the apiserver the deployment must use a dedicated service
account with limited RBAC permission. Otherwise no service account should be used.
On top of that, the container image for the Runtime Extension should be carefully designed in order to avoid
privilege escalation (e.g using distroless base images).
The Pod spec in the Deployment manifest should enforce security best practices (e.g. do not use privileged pods).
The default configuration engine for bootstrapping workload cluster machines is cloud-init. Ignition is an alternative engine used by Linux distributions such as Flatcar Container Linux and Fedora CoreOS and therefore should be used when choosing an Ignition-based distribution as the underlying OS for workload clusters.
This guide explains how to deploy an AWS workload cluster using Ignition.
Before workload clusters can be deployed, Cluster API components must be deployed to the management cluster.
Initialize the management cluster:
export AWS_REGION=us-east-1
export AWS_ACCESS_KEY_ID=AKIAIOSFODNN7EXAMPLE
export AWS_SECRET_ACCESS_KEY=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
# Workload clusters need to call the AWS API as part of their normal operation.
# The following command creates a CloudFormation stack which provisions the
# necessary IAM resources to be used by workload clusters.
clusterawsadm bootstrap iam create-cloudformation-stack
# The management cluster needs to call the AWS API in order to manage cloud
# resources for workload clusters. The following command tells clusterctl to
# store the AWS credentials provided before in a Kubernetes secret where they
# can be retrieved by the AWS provider running on the management cluster.
export AWS_B64ENCODED_CREDENTIALS=$(clusterawsadm bootstrap credentials encode-as-profile)
# Enable the feature gates controlling Ignition bootstrap.
export EXP_KUBEADM_BOOTSTRAP_FORMAT_IGNITION=true # Used by the kubeadm bootstrap provider
export EXP_BOOTSTRAP_FORMAT_IGNITION=true # Used by the AWS provider
# Initialize the management cluster.
clusterctl init --infrastructure aws
# Deploy the workload cluster in the following AWS region.
export AWS_REGION=us-east-1
# Authorize the following SSH public key on cluster nodes.
export AWS_SSH_KEY_NAME=my-key
# Ignition bootstrap data needs to be stored in an S3 bucket so that nodes can
# read them at boot time. Store Ignition bootstrap data in the following bucket.
export AWS_S3_BUCKET_NAME=my-bucket
# Set the EC2 machine size for controllers and workers.
export AWS_CONTROL_PLANE_MACHINE_TYPE=t3a.small
export AWS_NODE_MACHINE_TYPE=t3a.small
clusterctl generate cluster ignition-cluster \
--from https://github.com/kubernetes-sigs/cluster-api-provider-aws/blob/main/templates/cluster-template-flatcar.yaml \
--kubernetes-version v1.28.0 \
--worker-machine-count 2 \
> ignition-cluster.yaml
NOTE: Only certain Kubernetes versions have pre-built Kubernetes AMIs. See list of published pre-built Kubernetes AMIs.
Wait for the control plane of the workload cluster to become initialized:
kubectl get kubeadmcontrolplane ignition-cluster-control-plane
This could take a while. When the control plane is initialized, the INITIALIZED field should be true:
NAME CLUSTER INITIALIZED API SERVER AVAILABLE REPLICAS READY UPDATED UNAVAILABLE AGE VERSION
ignition-cluster-control-plane ignition-cluster true 1 1 1 7m7s v1.22.2
clusterctl get kubeconfig ignition-cluster > ./kubeconfig
Set kubectl to use the generated kubeconfig:
export KUBECONFIG=$(pwd)/kubeconfig
Verify connectivity with the workload cluster’s API server:
kubectl cluster-info
Sample output:
Kubernetes control plane is running at https://ignition-cluster-apiserver-284992524.us-east-1.elb.amazonaws.com:6443
CoreDNS is running at https://ignition-cluster-apiserver-284992524.us-east-1.elb.amazonaws.com:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
A CNI plugin must be deployed to the workload cluster for the cluster to become ready. We use Calico here, however other CNI plugins could be used, too.
NAME STATUS ROLES AGE VERSION
ip-10-0-122-154.us-east-1.compute.internal Ready control-plane,master 14m v1.22.2
ip-10-0-127-59.us-east-1.compute.internal Ready <none> 13m v1.22.2
ip-10-0-89-169.us-east-1.compute.internal Ready <none> 13m v1.22.2
Cluster API supports running multiple infrastructure/bootstrap/control plane providers on the same management cluster. It’s highly recommended to rely on
clusterctl init command in this case. clusterctl will help ensure that all providers support the same
API Version of Cluster API (contract).
All of the four images are hosted by registry.k8s.io. In order to verify the authenticity of the images, you can use cosign verify command with the appropriate image name and version:
Verification for registry.k8s.io/cluster-api/cluster-api-controller:v1.5.0 --
The following checks were performed on each of these signatures:
- The cosign claims were validated
- Existence of the claims in the transparency log was verified offline
- The code-signing certificate was verified using trusted certificate authority certificates
[
{
"critical": {
"identity": {
"docker-reference": "registry.k8s.io/cluster-api/cluster-api-controller"
},
"image": {
"docker-manifest-digest": "sha256:f34016d3a494f9544a16137c9bba49d8756c574a0a1baf96257903409ef82f77"
},
"type": "cosign container image signature"
},
"optional": {
"1.3.6.1.4.1.57264.1.1": "https://accounts.google.com",
"Bundle": {
"SignedEntryTimestamp": "MEYCIQDtxr/v3uRl2QByVfYo1oopruADSaH3E4wThpmkibJs8gIhAIe0odbk99na5GBdYGjJ6IwpFzhlTlicgWOrsgxZH8LC",
"Payload": {
"body": "eyJhcGlWZXJzaW9uIjoiMC4wLjEiLCJraW5kIjoiaGFzaGVkcmVrb3JkIiwic3BlYyI6eyJkYXRhIjp7Imhhc2giOnsiYWxnb3JpdGhtIjoic2hhMjU2IiwidmFsdWUiOiIzMDMzNzY0MTQwZmI2OTE5ZjRmNDg2MDgwMDZjYzY1ODU2M2RkNjE0NWExMzVhMzE5MmQyYTAzNjE1OTRjMTRlIn19LCJzaWduYXR1cmUiOnsiY29udGVudCI6Ik1FUUNJQ3RtcGdHN3RDcXNDYlk0VlpXNyt6Rm5tYWYzdjV4OTEwcWxlWGppdTFvbkFpQS9JUUVSSDErdit1a0hrTURSVnZnN1hPdXdqTTN4REFOdEZyS3NUMHFzaUE9PSIsInB1YmxpY0tleSI6eyJjb250ZW50IjoiTFMwdExTMUNSVWRKVGlCRFJWSlVTVVpKUTBGVVJTMHRMUzB0Q2sxSlNVTTJha05EUVc1SFowRjNTVUpCWjBsVldqYzNUbGRSV1VacmQwNTVRMk13Y25GWWJIcHlXa3RyYURjMGQwTm5XVWxMYjFwSmVtb3dSVUYzVFhjS1RucEZWazFDVFVkQk1WVkZRMmhOVFdNeWJHNWpNMUoyWTIxVmRWcEhWakpOVWpSM1NFRlpSRlpSVVVSRmVGWjZZVmRrZW1SSE9YbGFVekZ3WW01U2JBcGpiVEZzV2tkc2FHUkhWWGRJYUdOT1RXcE5kMDU2U1RGTlZHTjNUa1JOTlZkb1kwNU5hazEzVG5wSk1VMVVZM2hPUkUwMVYycEJRVTFHYTNkRmQxbElDa3R2V2tsNmFqQkRRVkZaU1V0dldrbDZhakJFUVZGalJGRm5RVVZ4VEdveFJsSmhLM2RZTUVNd0sxYzFTVlZWUW14UmRsWkNWM2xLWTFRcmFWaERjV01LWTA4d1prVmpNV2s0TVUxSFQwRk1lVXB2UXpGNk5TdHVaRGxFUnpaSGNFSmpOV0ZJYXpoU1QxaDBOV2h6U21wa1VVdFBRMEZhUVhkblowZE5UVUUwUndwQk1WVmtSSGRGUWk5M1VVVkJkMGxJWjBSQlZFSm5UbFpJVTFWRlJFUkJTMEpuWjNKQ1owVkdRbEZqUkVGNlFXUkNaMDVXU0ZFMFJVWm5VVlYxTVRoMENqWjVWMWxNVlU5RVR5dEVjek52VVU1RFNsYzNZMUJWZDBoM1dVUldVakJxUWtKbmQwWnZRVlV6T1ZCd2VqRlphMFZhWWpWeFRtcHdTMFpYYVhocE5Ga0tXa1E0ZDFGQldVUldVakJTUVZGSUwwSkVXWGRPU1VWNVlUTktiR0pETVRCamJsWjZaRVZDY2s5SVRYUmpiVlp6V2xjMWJreFlRbmxpTWxGMVlWZEdkQXBNYldSNldsaEtNbUZYVG14WlYwNXFZak5XZFdSRE5XcGlNakIzUzFGWlMwdDNXVUpDUVVkRWRucEJRa0ZSVVdKaFNGSXdZMGhOTmt4NU9XaFpNazUyQ21SWE5UQmplVFZ1WWpJNWJtSkhWWFZaTWpsMFRVTnpSME5wYzBkQlVWRkNaemM0ZDBGUlowVklVWGRpWVVoU01HTklUVFpNZVRsb1dUSk9kbVJYTlRBS1kzazFibUl5T1c1aVIxVjFXVEk1ZEUxSlIwdENaMjl5UW1kRlJVRmtXalZCWjFGRFFraDNSV1ZuUWpSQlNGbEJNMVF3ZDJGellraEZWRXBxUjFJMFl3cHRWMk16UVhGS1MxaHlhbVZRU3pNdmFEUndlV2RET0hBM2J6UkJRVUZIU21wblMxQmlkMEZCUWtGTlFWSjZRa1pCYVVKSmJXeGxTWEFyTm05WlpVWm9DbWRFTTI1Uk5sazBSV2g2U25SVmMxRTRSSEJrWTFGeU5FSk1XRE41ZDBsb1FVdFhkV05tYmxCUk9GaExPWGRZYkVwcVNWQTBZMFpFT0c1blpIazRkV29LYldreGN6RkRTamczTW1zclRVRnZSME5EY1VkVFRUUTVRa0ZOUkVFeVkwRk5SMUZEVFVoaU9YRjBSbGQxT1VGUU1FSXpaR3RKVkVZNGVrazRZVEkxVUFwb2IwbFBVVlJLVWxKeGFsVmlUMkUyVnpOMlRVZEJOWFpKTlZkVVJqQkZjREZwTWtGT2QwbDNSVko0TW5ocWVtWjNjbmRPYmxoUVpEQjRjbmd3WWxoRENtUmpOV0Z4WWxsWlVsRXdMMWhSVVdONFRFVnRkVGwzUnpGRlYydFNNWE01VEdaUGVHZDNVMjRLTFMwdExTMUZUa1FnUTBWU1ZFbEdTVU5CVkVVdExTMHRMUW89In19fX0=",
"integratedTime": 1690304684,
"logIndex": 28719030,
"logID": "c0d23d6ad406973f9559f3ba2d1ca01f84147d8ffc5b8445c224f98b9591801d"
}
},
"Issuer": "https://accounts.google.com",
"Subject": "krel-trust@k8s-releng-prod.iam.gserviceaccount.com",
"org.kubernetes.kpromo.version": "kpromo-v4.0.3-5-ge99897c"
}
}
]
With CAPI v1.6 we introduced new flags to allow serving metrics, the pprof endpoint and an endpoint to dynamically change log levels securely in production.
As soon as the feature is enabled the metrics endpoint is served via https and protected via authentication and authorization. This works the same way as
metrics in core Kubernetes components: Metrics in Kubernetes.
To continue serving metrics via http the following configuration can be used:
A ServiceAccount token is now required to scrape metrics. The corresponding ServiceAccount needs permissions on the /metrics path.
This can be achieved e.g. by following the Kubernetes documentation.
With the Prometheus Helm chart it is as easy as using the following config for the Prometheus job scraping the Cluster API controllers:
scheme: https
authorization:
type: Bearer
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
# The diagnostics endpoint is using a self-signed certificate, so we don't verify it.
insecure_skip_verify: true
For more details please see our Prometheus development setup: Prometheus
Note: The Prometheus Helm chart deploys the required ClusterRole out-of-the-box.
The ClusterResourceSet feature is introduced to provide a way to automatically apply a set of resources (such as CNI/CSI) defined by users to matching newly-created/existing clusters.
ClusterResourceSet provides a basic solution for installing & managing resources, while for advanced use cases an addon provider must be used.
Feature gate name: ClusterResourceSet
Variable name to enable/disable the feature gate: EXP_CLUSTER_RESOURCE_SET
The ClusterResourceSet feature is now GA and is enabled by default, but can be disabled by setting the EXP_CLUSTER_RESOURCE_SET environment variable to false.
Suppose you want to automatically install the relevant external cloud provider on all workload clusters.
This can be accomplished by labeling the clusters with the specific cloud (e.g. AWS, GCP or OpenStack) and then creating a ClusterResourceSet for each.
For example, you could have the following for OpenStack:
This ClusterResourceSet would apply the content of the Secretcloud-config and of the ConfigMapcloud-provider-openstack in all workload clusters with the label cloud=openstack.
Suppose you have the file cloud.conf that should be included in the Secret and cloud-provider-openstack.yaml that should be in the ConfigMap.
The Secret and ConfigMap can then be created in the following way:
The strategy field is immutable so existing CRS can’t be updated directly. However, CAPI won’t delete the managed resources in the target cluster when the CRS is deleted.
So if you want to start using the Reconcile strategy, delete your existing CRS and create it again with the updated strategy.
Pod Security Admission allows applying Pod Security Standards during creation of pods at the cluster level.
The flavor development-topology for the Docker provider used in Quick Start already includes a basic Pod Security Standard configuration.
It is using ClusterClass variables and patches to inject the configuration.
By adding the following variables and patches Pod Security Standards can be added to every ClusterClass which references a Kubeadm based control plane.
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
spec:
variables:
- name: podSecurityStandard
required: false
schema:
openAPIV3Schema:
type: object
properties:
enabled:
type: boolean
default: true
description: "enabled enables the patches to enable Pod Security Standard via AdmissionConfiguration."
enforce:
type: string
default: "baseline"
description: "enforce sets the level for the enforce PodSecurityConfiguration mode. One of privileged, baseline, restricted."
pattern: "privileged|baseline|restricted"
audit:
type: string
default: "restricted"
description: "audit sets the level for the audit PodSecurityConfiguration mode. One of privileged, baseline, restricted."
pattern: "privileged|baseline|restricted"
warn:
type: string
default: "restricted"
description: "warn sets the level for the warn PodSecurityConfiguration mode. One of privileged, baseline, restricted."
pattern: "privileged|baseline|restricted"
...
The version field in Pod Security Admission Config defaults to latest.
The kube-system namespace is exempt from Pod Security Standards enforcement, because it runs control-plane pods that need higher privileges.
After adding the variables and patches the Pod Security Standards would be applied by default.
It is also possible to disable this patch or configure different levels for the configuration
using variables.
The clusterctl CLI tool handles the lifecycle of a Cluster API management cluster.
The clusterctl command line interface is specifically designed for providing a simple “day 1 experience” and a
quick start with Cluster API. It automates fetching the YAML files defining provider components and installing them.
Additionally it encodes a set of best practices in managing providers, that helps the user in avoiding
mis-configurations or in managing day 2 operations such as upgrades.
Below you can find a list of main clusterctl commands:
While using providers hosted on GitHub, clusterctl is calling GitHub API which are rate limited; for normal usage free tier is enough but when using clusterctl extensively users might hit the rate limit.
To avoid rate limiting for the public repos set the GITHUB_TOKEN environment variable. To generate a token follow this documentation. The token only needs repo scope for clusterctl.
Per default clusterctl will use a go proxy to detect the available versions to prevent additional
API calls to the GitHub API. It is possible to configure the go proxy url using the GOPROXY variable as
for go itself (defaults to https://proxy.golang.org).
To immediately fallback to the GitHub client and not use a go proxy, the environment variable could get set to
GOPROXY=off or GOPROXY=direct.
If a provider does not follow Go’s semantic versioning, clusterctl may fail when detecting the correct version.
In such cases, disabling the go proxy functionality via GOPROXY=off should be considered.
The clusterctl init command automatically adds the cluster-api core provider, the kubeadm bootstrap provider, and
the kubeadm control-plane provider to the list of providers to install. This allows users to use a concise command syntax for initializing a management cluster.
For example, to get a fully operational management cluster with the aws infrastructure provider, the cluster-api core provider, the kubeadm bootstrap, and the kubeadm control-plane provider, use the command:
The clusterctl init command by default installs each provider in the default target namespace defined by each provider, e.g. capi-system for the Cluster API core provider.
To access provider specific information, such as the components YAML to be used for installing a provider,
clusterctl init accesses the provider repositories, that are well-known places where the release assets for
a provider are published.
Per default clusterctl will use a go proxy to detect the available versions to prevent additional
API calls to the GitHub API. It is possible to configure the go proxy url using the GOPROXY variable as
for go itself (defaults to https://proxy.golang.org).
To immediately fallback to the GitHub client and not use a go proxy, the environment variable could get set to
GOPROXY=off or GOPROXY=direct.
If a provider does not follow Go’s semantic versioning, clusterctl may fail when detecting the correct version.
In such cases, disabling the go proxy functionality via GOPROXY=off should be considered.
An additional Provider object is created in the target namespace where the provider is installed.
This object keeps track of the provider version, and other useful information
for the inventory of the providers currently installed in the management cluster.
Cluster API providers require a cert-manager version supporting the cert-manager.io/v1 API to be installed in the cluster.
While doing init, clusterctl checks if there is a version of cert-manager already installed. If not, clusterctl will
install a default version (currently cert-manager v1.17.1). See clusterctl configuration for
available options to customize this operation.
Generates a YAML file named my-cluster.yaml with a predefined list of Cluster API objects; Cluster, Machines,
Machine Deployments, etc. to be deployed in the current namespace (in case, use the --target-namespace flag to
specify a different target namespace).
Then, the file can be modified using your editor of choice; when ready, run the following command
to apply the cluster manifest.
The clusterctl generate cluster command uses smart defaults in order to simplify the user experience; in the example above,
it detects that there is only an aws infrastructure provider in the current management cluster and so it automatically
selects a cluster template from the aws provider’s repository.
In case there is more than one infrastructure provider, the following syntax can be used to select which infrastructure
provider to use for the workload cluster:
The infrastructure provider authors can provide different types of cluster templates, or flavors; use the --flavor flag
to specify which flavor to use; e.g.
clusterctl uses the provider’s repository as a primary source for cluster templates; the following alternative sources
for cluster templates can be used as well:
Use the --from flag to read cluster templates stored in a GitHub repository, raw template URL, in a local file system folder,
or from the standard input; e.g.
If the selected cluster template expects some environment variables, the user should ensure those variables are set in advance.
E.g. if the AWS_CREDENTIALS variable is expected for a cluster template targeting the aws infrastructure, you
should ensure the corresponding environment variable to be set before executing clusterctl generate cluster.
Please refer to the providers documentation for more info about the required variables or use the
clusterctl generate cluster --list-variables flag to get a list of variables names required by a cluster template.
clusterctl fetches the provider components from the provider repository and performs variable substitution.
Variable values are either sourced from the clusterctl config file or
from environment variables
Usage: clusterctl generate provider [flags]
Current usage of the command is as follows:
# Generates a yaml file for creating provider with variable values using
# components defined in the provider repository.
clusterctl generate provider --infrastructure aws
# Generates a yaml file for creating provider for a specific version with variable values using
# components defined in the provider repository.
clusterctl generate provider --infrastructure aws:v0.4.1
# Displays information about a specific infrastructure provider.
# If applicable, prints out the list of required environment variables.
clusterctl generate provider --infrastructure aws --describe
# Displays information about a specific version of the infrastructure provider.
clusterctl generate provider --infrastructure aws:v0.4.1 --describe
# Generates a yaml file for creating provider for a specific version.
# No variables will be processed and substituted using this flag
clusterctl generate provider --infrastructure aws:v0.4.1 --raw
The clusterctl generate yaml command processes yaml using clusterctl’s yaml
processor.
The intent of this command is to allow users who may have specific templates
to leverage clusterctl’s yaml processor for variable substitution. For
example, this command can be leveraged in local and CI scripts or for
development purposes.
clusterctl ships with a simple yaml processor that performs variable
substitution that takes into account default values.
Under the hood, clusterctl’s yaml processor uses
drone/envsubst to replace variables and uses the defaults if
necessary.
Variable values are either sourced from the clusterctl config file or
from environment variables.
Current usage of the command is as follows:
# Generates a configuration file with variable values using a template from a
# specific URL as well as a GitHub URL.
clusterctl generate yaml --from https://github.com/foo-org/foo-repository/blob/main/cluster-template.yaml
clusterctl generate yaml --from https://foo.bar/cluster-template.yaml
# Generates a configuration file with variable values using
# a template stored locally.
clusterctl generate yaml --from ~/workspace/cluster-template.yaml
# Prints list of variables used in the local template
clusterctl generate yaml --from ~/workspace/cluster-template.yaml --list-variables
# Prints list of variables from template passed in via stdin
cat ~/workspace/cluster-template.yaml | clusterctl generate yaml --from - --list-variables
# Default behavior for this sub-command is to read from stdin.
# Generate configuration from stdin
cat ~/workspace/cluster-template.yaml | clusterctl generate yaml
The clusterctl describe cluster command provides an “at a glance” view of a Cluster API cluster designed
to help the user in quickly understanding if there are problems and where.
For example clusterctl describe cluster capi-quickstart will provide an output similar to:
The “at a glance” view is based on the idea that clusterctl should avoid overloading the user with information,
but instead surface problems, if any.
In practice, if you look at the ControlPlane node, you might notice that the underlying machines
are grouped together, because all of them have the same state (Ready equal to True), so it is not
necessary to repeat the same information three times.
If this is not the case, and machines have different states, the visualization is going to use different lines:
You might also notice that the visualization does not represent the infrastructure machine or the
bootstrap object linked to a machine, unless their state differs from the machine’s state.
By default, the visualization generated by clusterctl describe cluster hides details for the sake
of simplicity and shortness. However, if required, the user can ask for showing all the detail:
By using --grouping=false, the user can force the visualization to show all the machines
on separated lines, no matter if they have the same state or not:
By using the --echo flag, the user can force the visualization to show infrastructure machines and
bootstrap objects linked to machines, no matter if they have the same state or not:
It is also possible to force the visualization to show all the conditions for an object (instead of showing
only the ready condition). e.g. with --show-conditions KubeadmControlPlane you get:
Please note that this option is flexible, and you can pass a comma separated list of kind or kind/name for
which the command should show all the object’s conditions (use ‘all’ to show conditions for everything).
The clusterctl move command allows to move the Cluster API objects defining workload clusters, like e.g. Cluster, Machines,
MachineDeployments, etc. from one management cluster to another management cluster.
To move the Cluster API objects existing in the current namespace of the source management cluster; in case if you want
to move the Cluster API objects defined in another namespace, you can use the --namespace flag.
The discovery mechanism for determining the objects to be moved is in the provider contract
Pivoting is a process for moving the provider components and declared Cluster API resources from a source management
cluster to a target management cluster.
This can now be achieved with the following procedure:
Use clusterctl init to install the provider components into the target management cluster
Use clusterctl move to move the cluster-api resources from a Source Management cluster to a Target Management cluster
The pivot process can be bounded with the creation of a temporary bootstrap cluster
used to provision a target Management cluster.
This can now be achieved with the following procedure:
Create a temporary bootstrap cluster, e.g. using kind or minikube
Use clusterctl init to install the provider components
Use clusterctl generate cluster ... | kubectl apply -f - to provision a target management cluster
Wait for the target management cluster to be up and running
Get the kubeconfig for the new target management cluster
Use clusterctl init with the new cluster’s kubeconfig to install the provider components
Use clusterctl move to move the Cluster API resources from the bootstrap cluster to the target management cluster
Delete the bootstrap cluster
Note: It’s required to have at least one worker node to schedule Cluster API workloads (i.e. controllers).
A cluster with a single control plane node won’t be sufficient due to the NoSchedule taint. If a worker node isn’t available, clusterctl init will timeout.
With --dry-run option you can dry-run the move action by only printing logs without taking any actual actions. Use log level verbosity -v to see different levels of information.
The clusterctl upgrade command can be used to upgrade the version of the Cluster API providers (CRDs, controllers)
installed into a management cluster.
The clusterctl upgrade plan command can be used to identify possible targets for upgrades.
clusterctl upgrade plan
Produces an output similar to this:
Checking cert-manager version...
Cert-Manager will be upgraded from "v1.5.0" to "v1.5.3"
Checking new release availability...
Management group: capi-system/cluster-api, latest release available for the v1beta1 API Version of Cluster API (contract):
NAME NAMESPACE TYPE CURRENT VERSION NEXT VERSION
bootstrap-kubeadm capi-kubeadm-bootstrap-system BootstrapProvider v0.4.0 v1.0.0
control-plane-kubeadm capi-kubeadm-control-plane-system ControlPlaneProvider v0.4.0 v1.0.0
cluster-api capi-system CoreProvider v0.4.0 v1.0.0
infrastructure-docker capd-system InfrastructureProvider v0.4.0 v1.0.0
You can now apply the upgrade by executing the following command:
clusterctl upgrade apply --contract v1beta1
The output contains the latest release available for each Cluster API contract version.
available at the moment.
After choosing the desired option for the upgrade, you can run the following
command to upgrade all the providers in the management cluster. This upgrades
all the providers to the latest stable releases.
clusterctl upgrade apply --contract v1beta1
The upgrade process is composed by three steps:
Check the cert-manager version, and if necessary, upgrade it.
Delete the current version of the provider components, while preserving the namespace where the provider components
are hosted and the provider’s CRDs.
Install the new version of the provider components.
Please note that clusterctl does not upgrade Cluster API objects (Clusters, MachineDeployments, Machine etc.); upgrading
such objects are the responsibility of the provider’s controllers.
It is also possible to explicitly upgrade one or more components to specific versions.